Работа в интерфейсе администратора
Вход и основное меню
Аминистративное приложение не требует установки на рабочие станции пользователей, не требует никакого дополнительного ПО или библиотек. Для работы данного web-приложения достаточно интернет браузера (рекомендуется Google Chrome).
Вход осуществляется только через данную форму. Форма доступна только для внутренних пользователей системы и только по ссылке, содержащей «/adminpanel».
После успешной аутентификации отображается форма со списком сессий. Нажмите на иконку  , чтобы перейти в панель администратора.
, чтобы перейти в панель администратора.
В правом верхнем углу отображаются элементы, при помощи которых можно:
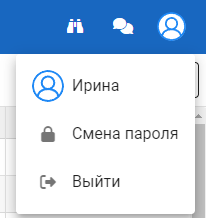
- Перейти в интерфейс оператора.
- Перейти в интерфейс чата.
- Открыть меню пользователя, содержащее следующие пункты:
- Имя пользователя (не кликабельно).
- Смена пароля локальной учетной записи.
- Выход из панели администратора.
Смена пароля
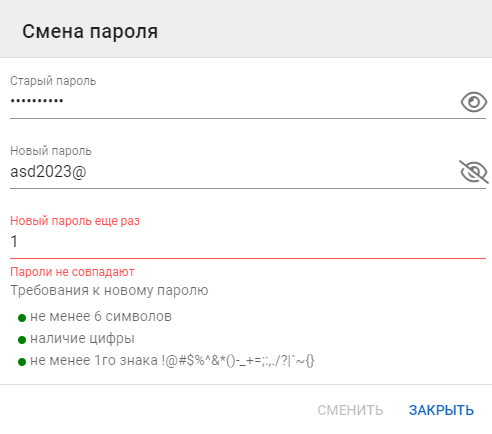
На данной форме:
-
Укажите старый пароль от учетной записи (его проверка на валидность происходит в момент смены пароля).
-
Два раза укажите новый пароль (требования к новому паролю будут отмечаться зеленым по мере их выполнения).
Основное меню
В левом верхнем углу находится основное меню для навигации по функциональным блокам панели администратора.
Чтобы свернуть/развернуть левое навигационное меню, нажмите на кнопку справа от него:
Основное меню административной панели содержит следующие разделы:
- UI. Скилсеты — управление наборами знаний внутри текущего сервера.
- UI. Документы — управление документами (для диалоговых сценариев, связанных с получением документа, например, инструкции по процессу).
- UI. Настройки — управление основными настройками системы.
- UI. Пользователи — управление пользователями и ролями текущего сервера.
- UI. Логи — просмотр и управление журналом событий.
- UI. Статистика — просмотр статистики всех сессий текущего сервера.
- UI. Информация — информация об установленных компонентах и версиях, а также информация об API.
- UI. Дополнительно — настраиваемая панель быстрого доступа.
Скилсеты (Skillsets)
Форма со скилсетами выглядит следующим образом:
Без скилсет репозитория:
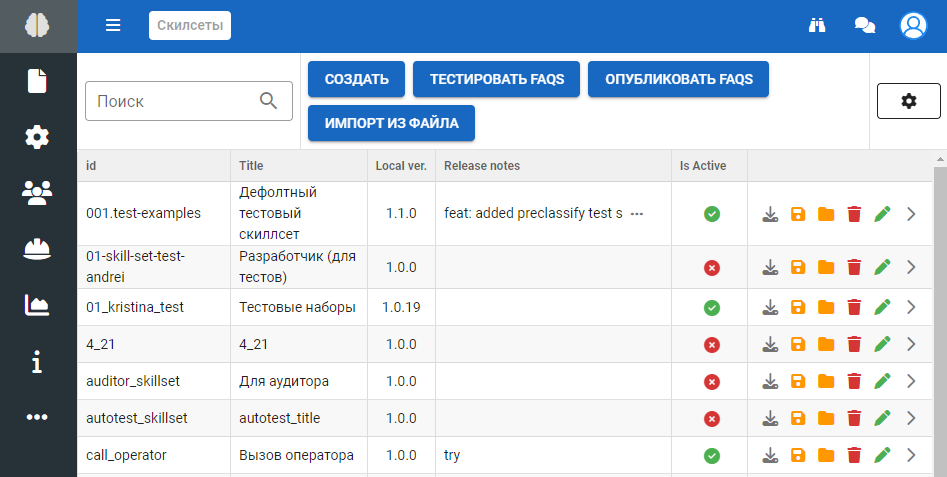
С подключенным скилсет репозиторием:
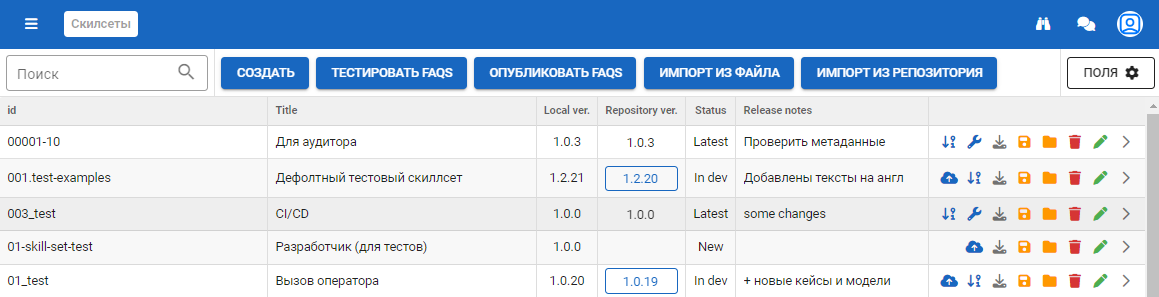
На форме присутствует:
- Строка поиска.
- Кнопки добавления скилсетов (Создать, Импорт из файла и Импорт из репозитория).
- Кнопка Поля, которая отвечает за настройки полей для отображения информации о скилсетах.
- Таблица отображения информации и возможных действий скилсетов.
Основной блок содержит список всех скилсетов текущего сервера, основные параметры и элементы управления каждым скилсетом.
Параметры скилсета:
| № | Наименование | Описание |
|---|---|---|
| 1 | id | Уникальное имя скилсета, используемое при разработке. Недоступно для пользователя. |
| 2 | Title | Название скилсета на языке текущего сервера, которое видит пользователь. |
| 3 | Local ver. | Отображается только при подключенном npm репозитории для скилсетов. Локальная версия скилсета. |
| 4 | Repository ver. | Отображается только при подключенном npm репозитории для скилсетов. Версия скилсета, которая находится в репозитории. |
| 5 | Repositore tag | Отображается только при подключенном npm репозитории для скилсетов. Метки на скилсетах в npm репозитории, позволяющие определить, какие сейчас производятся действия над скилсетом, на каком стенде скилсет доступен и прочее. |
| 6 | Status | Отображается только при подключенном npm репозитории для скилсетов. Статус скилсета, который вычисляется, исходя из версий. |
| 7 | Release notes | Комментарий к скилсету. Обычно используется, чтобы описать изменения в скилсете. |
| 8 | Is Active | Флаг активности, параметр отображения скилсета пользователю при выдаче choice. Если после двух попыток выяснить цель пользователя система не смогла подобрать скилсет, в чат выводится список доступных пользователю скилсетов с возможностью выбора (choice). Если в поле active указано значение неактивен, то пользователь не увидит этот скилсет среди choice. |
| 9 | Is Shared | Флаг, который отвечает за возможность использования элементов скилсета другими скилсетами. |
| 10 | Exclude FAQ | Флаг, который исключает скилсет для формирования глобальной FAQ модели. |
| 11 | Roles | Список ролей пользователей, которым доступны сценарии диалогов данного скилсета. |
Панель управления скилсетом (порядок соответствует порядку на форме):
| № | Наименование | Иконка | Описание |
|---|---|---|---|
| 1 | Опубликовать в репозиторий |  |
Публикует скилсет в выбранный репозиторий, для возможности его импорта на другом инстансе VK Assistant. |
| 2 | Редактирование тегов |  |
Позволяет добавлять и удалять теги в репозитории на определенной версии скилсета. |
| 3 | Вернуть на предыдущую версию |  |
Позволяет откатится на предыдущую версию скилсета, который есть в репозитории. |
| 4 | Начать редактирование |  |
Позволяет повысить версию скилсету и начать выполнять изменения в нем. |
| 5 | Экспорт |  |
Экспорт в виде файла формата JSON. Позволяет скачать структуру скилсета с сохранением всех названий сущностей. Важно: экспортированный скилсет не включает сущности, на которые он ссылается, а также агентов, платформы и роли. |
| 6 | Слепок |  |
Создание слепка (текущего состояния) скилсета на сервере без загрузки на локальный диск. Обладает всеми свойствами функции Export. Используется в качестве резервной копии скилсета перед внесении изменений. Автоматически сгенерированный снапшот с названием «Autogenerated snapshot after SkillSet Delete» создается при удалении скилсета. Появляется при загрузке или создании пустого скилсета с таким же id. Автоматически сгенерированный снапшот с названием «Autogenerated snapshot after SkillSet Delete» создается так же при импорте скилсета с id, который совпадает с существующим. |
| 7 | Открыть список слепков |  |
Просмотр списка сохраненных слепков. Хранит название скилсета, имя пользователя, сделавшего слепок, версию и дату слепка. Список позволяет экспортировать слепок на локальный диск, восстановить версию скилсета из слепка и удалить слепок. |
| 8 | Удалить |  |
Удаление скилсета с текущего инстанса VK Assistant. |
| 9 | Редактировать |  |
Редактирование поля title, версии, флага активности, изменение ролей пользователей и свойства. Важно: id скилсета изменить нельзя. |
| 10 | Смотреть |  |
Позволяет просматривать метаданные скилсета без возможности их редактировать. |
| 11 | Открыть детали |  |
Переход в дашборд скилсета и просмотр или изменение его составляющих. Поля на дашборде: - Персептроны — базовые элементы логики системы, содержащие алгоритм обработки событий и фактов в рамках диалога. - Факты — начальный набор фактов, на которые опирается логика скилсета. - Базы знаний — элементы базы знаний в рамках данного скилсета. - Тесты — созданные тесты, последовательность действий для проверки корректной работы. - Агенты — все специальные агенты, которые участвуют в прохождении сессии. - FAQs — база автоматических ответов для часто задаваемых вопросов по этому скилсету. - NLP экстракторы — инструменты для экстракции фактов из usertext. - NLP модели — инструменты для создания модели, в частности, отвечающие за классификацию текстов, например, текстов запросов (пользовательских обращений). - NLP датасеты — хранилище данных для классификации, наборы данных в формате класс (ключ) / текст (значение). |
Поиск скилсета
Для поиска скилсета необходимо ввести в строке поиска id или title скилсета.
Создание скилсета
Для создания нового скилсета необходимо нажать кнопку Создать и заполнить поля на отобразившейся форме, после чего начать Готово:
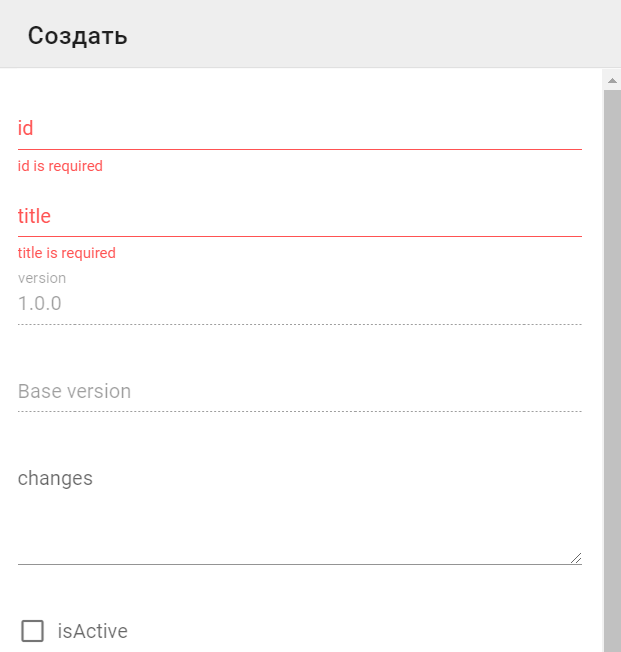
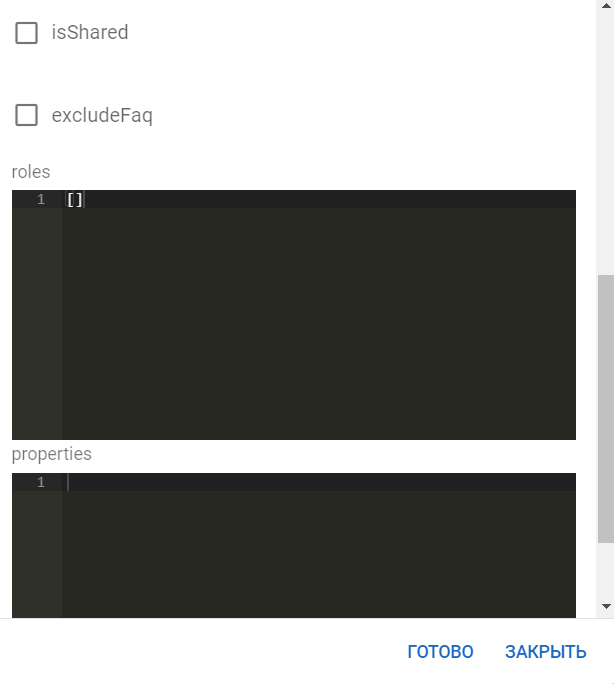
Импорт скилсета из файла
Чтобы загрузить предварительно скачанный готовый скилсет из другого инстанса, необходимо использовать кнопку Импорт из файла:
Настройка видимости полей
Чтобы настроить отображение параметров списка скилсетов, нажмите на кнопку  в правом верхнем углу.
На форме можно будет скрывать и добавлять поля. По умолчанию при каждой загрузке страницы отображаются все поля.
в правом верхнем углу.
На форме можно будет скрывать и добавлять поля. По умолчанию при каждой загрузке страницы отображаются все поля.
Персептроны (Perceptron)
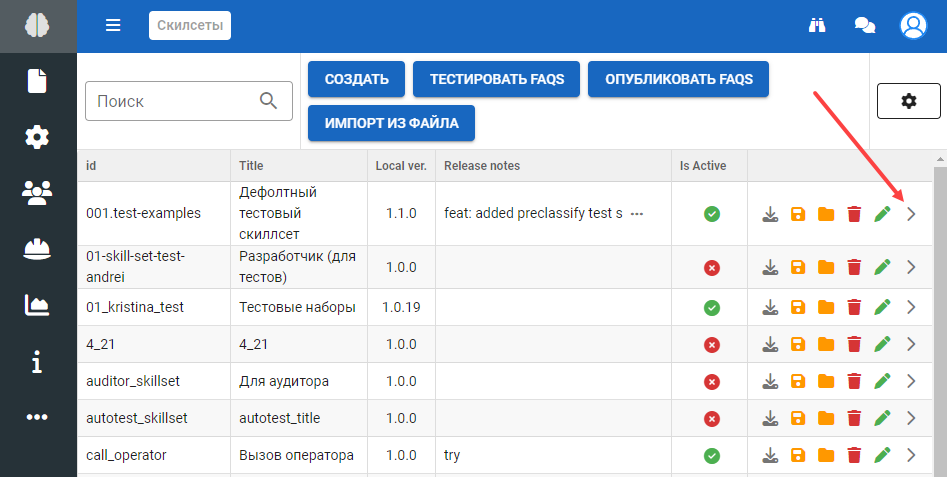
Чтобы просмотреть все персептроны скилсета нажмите на иконку :
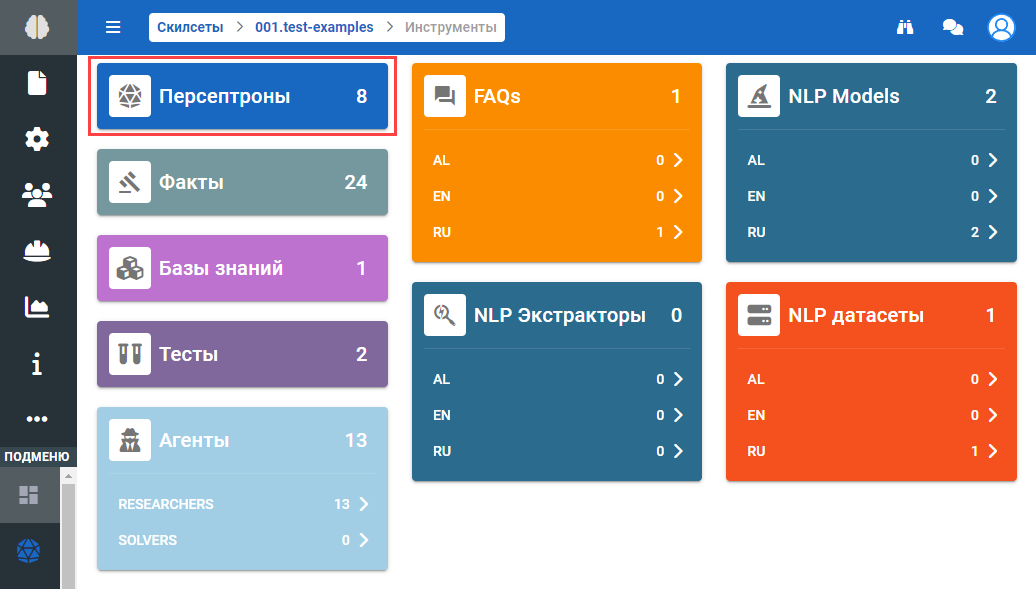
В отобразившемся подразделе Инструменты нажмите на блок Персептроны:
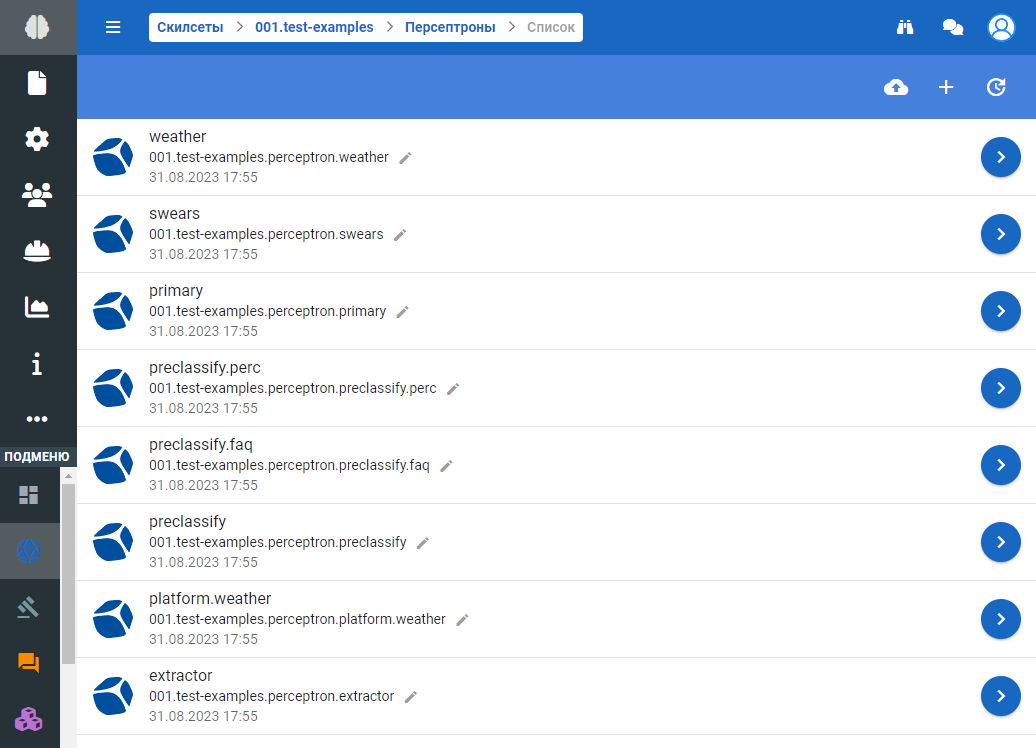
Откроется форма со списком персептронов данного скилсета:
Чтобы перейти в редактор персептрона, нажмите  справа напротив необходимого персептрона.
справа напротив необходимого персептрона.
Чтобы импортировать персептрон, нажмите  , выберите персептрон или перетащите его в отобразившееся поле.
Чтобы создать новый персептрон внутри данного скилсета, нажмите
, выберите персептрон или перетащите его в отобразившееся поле.
Чтобы создать новый персептрон внутри данного скилсета, нажмите  , задайте персептрону уникальный id в поле id, понятное имя на языке текущего сервера в поле Name и нажмите Создать:
, задайте персептрону уникальный id в поле id, понятное имя на языке текущего сервера в поле Name и нажмите Создать:
Чтобы открыть панель управления персептроном, нажмите на строку конкретного персептрона:

Панель управления персептроном:
| № | Наименование | Иконка | Описание |
|---|---|---|---|
| 1 | Создать слепок |  |
Сделать слепок персептрона. |
| 2 | Показать слепки |  |
Список слепков персептрона, используется в качестве резервной копии при внесении изменений. |
| 3 | Экспорт |  |
Экспортировать персептрон в файл формата JSON. |
| 4 | Удалить |  |
Удалить персептрон. |
| 5 | Редактировать |  |
Вы можете изменить имя персептрона и добавить/редактировать описание; id персептрона не изменяется. |
| 6 | Открыть редактор |  |
Осуществляет переход в графический редактор персептрона. |
Работа с персептроном
Разработчик сценариев, используя базовые элементы персептрона при помощи визуального конструктора, выполняет настройку персептронов в соответствии с задачей реализации ожидаемых сценариев диалога.

Диаграмма персептрона представляет собой схему, на которой отображены все сущности, участвующие в расчете персептрона, связи между ними, а также количественные коэффициенты нейронов персептрона:
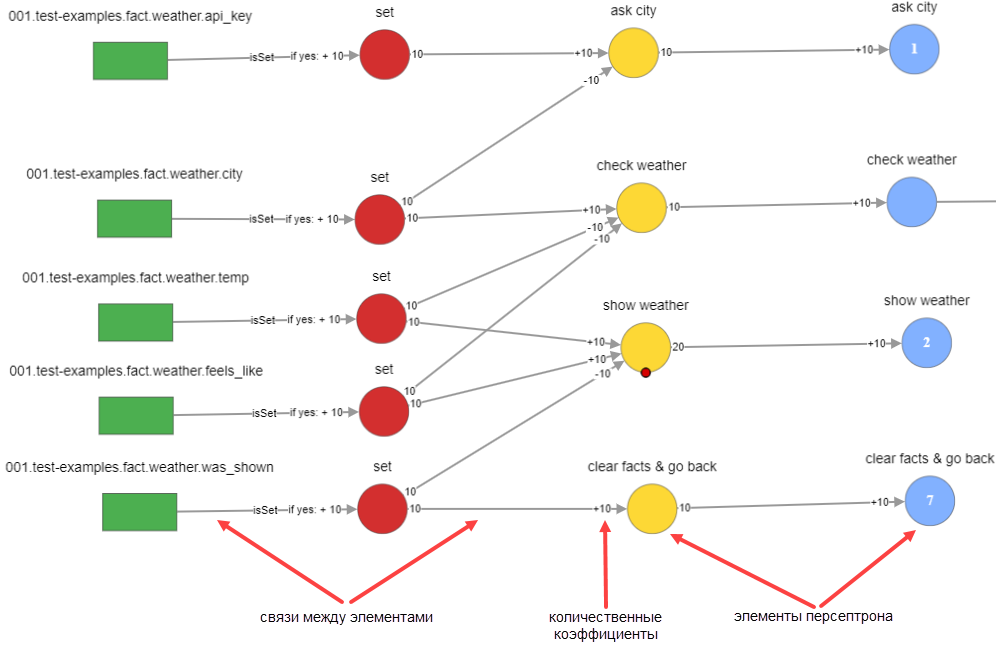
Каждый элемент на диаграмме персептрона имеет меню. Чтобы открыть меню, нажмите на элемент. Меню позволяет:
- просмотреть параметры элемента;
- совершить действия с элементом: показать элемент на диаграмме, удалить элемент и удалить элемент с диаграммы (только для фактов, элементов базы знаний и агентов);
- просмотреть связи элемента;
- редактировать параметры элемента.
Поиск элементов персептрона
В правом верхнем углу находится строка поиска, которая выдает список всех элементов персептрона. Чтобы найти элемент на диаграмме, выберите его в списке или начните писать его название/id в строке поиска:
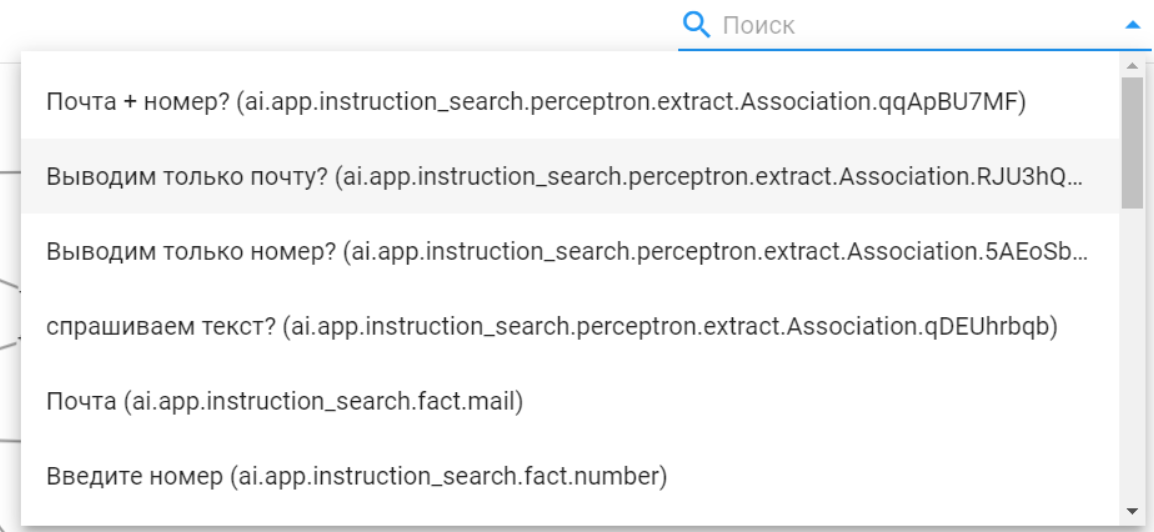
Создание элементов и связей на диаграмме
Чтобы добавить новую связь к элементу на диаграмме:
-
Наведите курсор на элемент, чтобы под ним появилась красная точка.
-
Проведите линию из красной точки к элементу, с которым необходимо осуществить связь.
Панель управления персептроном
Слева находится панель управления персептроном:
 — меню выбора сущностей скилсета.
— меню выбора сущностей скилсета.
 — дебаг-режим, предназначенный для работы с диаграммой персептрона.
— дебаг-режим, предназначенный для работы с диаграммой персептрона.
 — меню специальных агентов.
— меню специальных агентов.
 — тест-меню.
— тест-меню.
 — масштабировать персептрон на диаграмме.
— масштабировать персептрон на диаграмме.
 — упорядочить все элементы персептрона на диаграмме.
— упорядочить все элементы персептрона на диаграмме.
 — создавать новые элементы персептрона.
— создавать новые элементы персептрона.
Меню выбора сущностей скилсета:
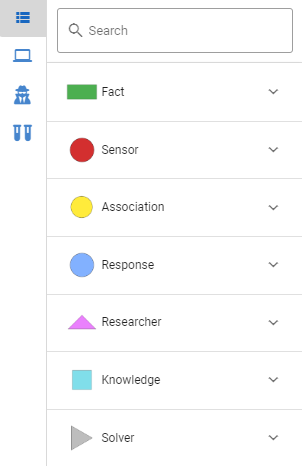
В списке представлены все факты, элементы базы знаний и агенты, которые доступны в данном скилсете. Чтобы найти необходимый элемент, используйте блок поиска.
Красной линией отмечены те факты, элементы базы знаний и агенты, которые использованы в данном персептроне и присутствуют на диаграмме персептрона.
В полях Sensor, Association и Responce отображаются только составляющие данного персептрона, представленные на диаграмме персептрона.
Чтобы просмотреть список элементов, нажмите на иконку  :
:
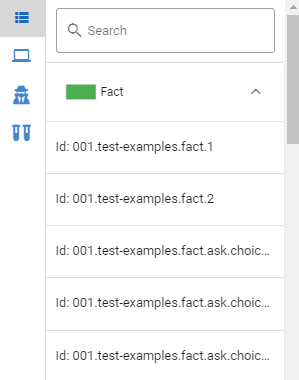
Дебаг-режим:
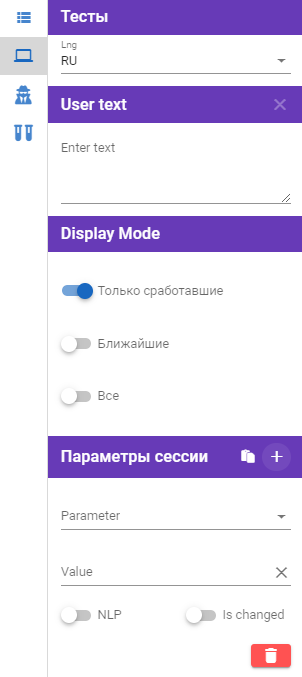
Дебаг-режим позволяет эмулировать определенную ветку диалога при заданном usertext.
В поле Lng (блок Тесты) можно выбрать любой из доступных для этого текущего сервера языков.
В поле Enter text (блок User text) вводится проверяемый usertext. Также его можно ввести в блоке Параметры сессии.
В блоке Display Mode доступен выбор режима отображения эмуляции ветки диалога:
- Только сработавшие — позволит увидеть на диаграмме только те сущности, которые сработали по выбранному факту/usertext.
- Ближайшие — позволит увидеть сработавшие сущности и их не сработавшие в этой ветке связи.
- Все.
В блоке Параметры сессии можно указать проверяемый факт (Parameter) и его ожидаемое значение (Value). Чтобы добавить параметр, нажмите на иконку  . Функция NLP используется для usertext, которые содержат NLP модели. При тестировании персептрона рекомендуется отключать эту функцию.
. Функция NLP используется для usertext, которые содержат NLP модели. При тестировании персептрона рекомендуется отключать эту функцию.
Факты (Fact)
Чтобы просмотреть факты скилсета нажмите на иконку :
В отобразившемся подразделе Инструменты нажмите на блок Факты:
В разделе Факты находится список всех фактов, используемых в данном скилсете:
Создание факта
Для создания нового факта нажмите на кнопку Создать. Все поля, помеченные звездочкой, обязательны для заполнения:
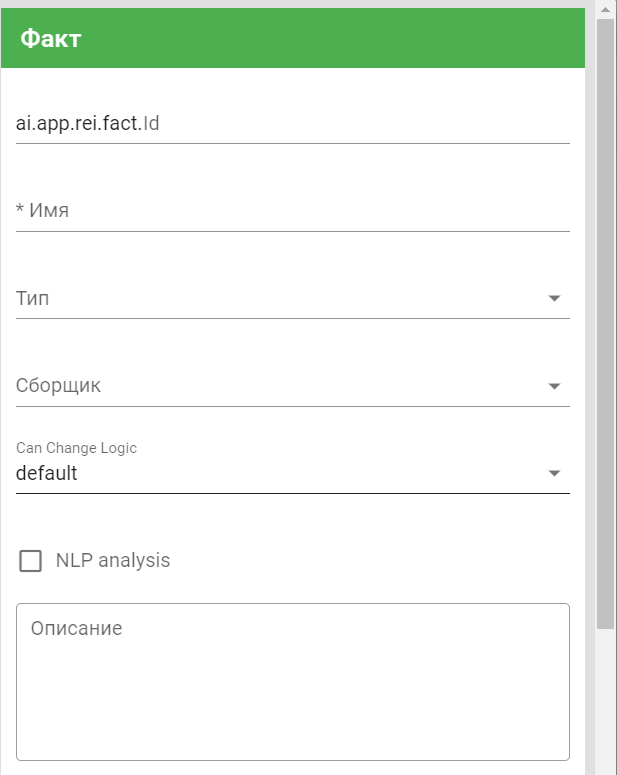
Перечень параметров:
- id — задать уникальное, неизменяемое имя факта.
- Имя — задать название факта на языке текущего сервера.
- Тип — неиспользуемое поле.
- Сборщик — указывается агент, который будет запущен при изменении данного факта.
- Can Change Logic) — реализация перехода в другой скилсет в рамках диалога.
- NLP analysis — задать необходимость запуска NLP-анализатора.
- Описание — обозначить дополнительную информацию о факте (при необходимости).
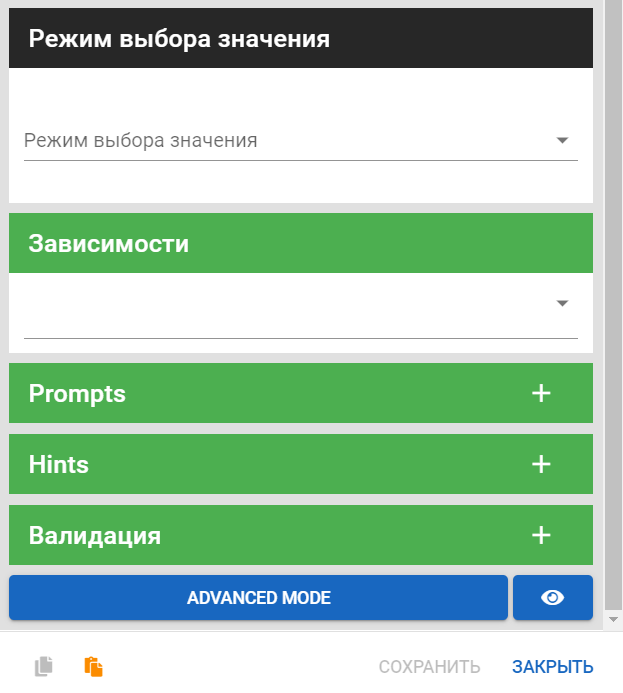
- Режим выбора значения — настроить выбор значения:
- Классификатор или choice from classify — для выбора значения по классификации введенного текста пользователя по заданным вариантам.
- Кнопки — для выбора значения по точному выбору из предлагаемого списка.
- isCustomInput — позволит писать сообщение в chat и built-in-chat, а не обязательно выбирать значение из списка. Возможны следующие варианты:
- Если текст сообщения совпадает с одним из вариантом choice или его порядковым номером, то отправляем выбранный вариант в VK Assistant.
- Если текст сообщения НЕ совпадает и параметр имеет значение true, то пропускать данный текст для дальнейшей возможности работы с ним в рамках сценария.
- Если текст сообщения НЕ совпадает и параметр имеет значение false или его нет, то не пропускать данный текст для дальнейшей возможности работы с ним в рамках сценария, а выводить стандартное сообщение.
- Дата — для выбора значения из календаря
- Агент — используется для запросов в целевые системы через встроенное веб-приложение.
- Зависимости — задать родительский факт из выпадающего списка.
- Prompts — сформулировать вопрос, с помощью которого система будет выяснять факт у пользователя.
- Hints — сформулировать объяснение факта для пользователя.
- Валидация — задать валидацию для факта.
- Advanced mode — режим для добавления особых параметров в виде кода на языке JavaScript, например, задать выпадающий список для пользователя.
Редактирование фактов
Важно
Редактирование фактов доступно только в том скилсете, в котором они были созданы. Редактирование параметров системных фактов доступно только в ядре.
Копирование фактов
Для переноса фактов между скилсетами используются кнопки 
Факт можно вставить ( ) в форму создания/редактирования, если он предварительно был скопирован посредством формы создания/редактирования.
) в форму создания/редактирования, если он предварительно был скопирован посредством формы создания/редактирования.
Копирование ( ) доступно, если в форме создания/редактирования заполнены все обязательные поля.
) доступно, если в форме создания/редактирования заполнены все обязательные поля.
Базы знаний (Knowledge base)
Чтобы просмотреть базы знаний скилсета нажмите на иконку :
В отобразившемся подразделе Инструменты нажмите на блок Базы знаний:
В этом разделе хранятся все элементы базы знаний, используемые в текущем скилсете

Создание базы знаний
Чтобы создать базу знаний, нажмите на кнопку Создать и заполните все обязательные поля:
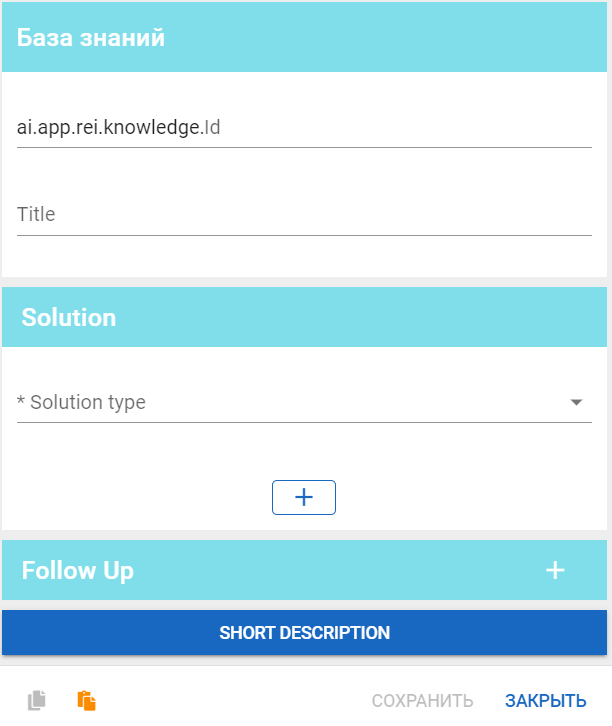
Перечень полей:
- id — уникальный идентификатор;
- Title — название на языке текущего сервера;
- Solution — умение из списка:
- none — управление отдается агенту Solver;
- url — пользователь переводится на другую страницу;
- text — в качестве решения выводится текст;
- html — в качестве решения выводится страница html;
- document — в качестве решения выводится документ. Ссылка на документ может формироваться двумя способами:
- для работы с файлом в текущей вкладке;
- для работы с файлом вне текущей вкладки (другое окно или вкладка).
- Follow up — указывается другая КБ, которая отработает, если агент solver, запустившийся после исходного КБ, вернет соответствующий код:
- knowledge - id базы знаний.
- code - код, который должен совпадать с ответом solvera.
- variant - результат работы solver'а.
- Short Description - описание БЗ.
Тесты
Чтобы просмотреть тесты скилсета нажмите на иконку :
В отобразившемся подразделе Инструменты нажмите на блок Тесты:
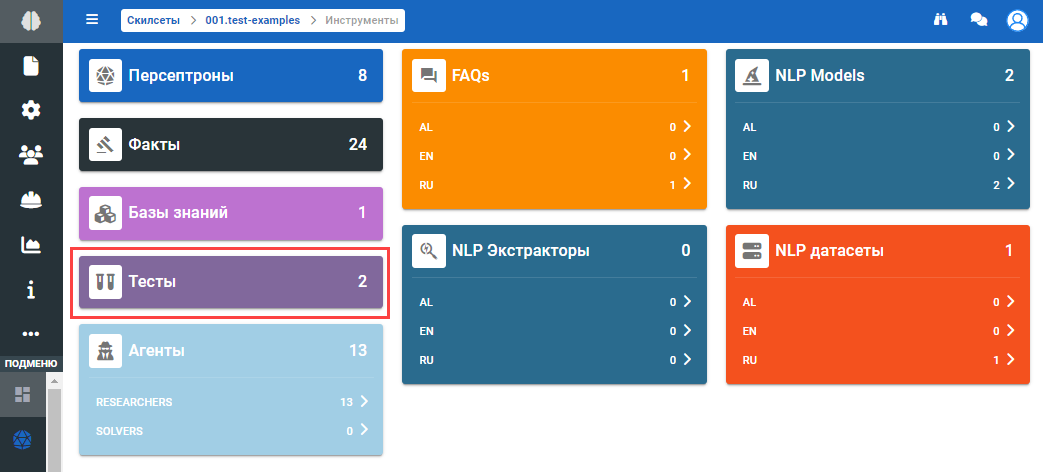
В блоке Тесты хранятся сохраненные сессии в удобном формате.
На главном экране расположен список папок с тестами:
Просмотр тестов
Чтобы перейти в список тестов конкретной папки с тестами, необходимо нажать на иконку .
Форма просмотра тестов в папке:

Перечень элементов:
-
кнопка Создать — для создания нового теста;
-
синяя кнопка Выполнить — запускает все тесты в данной папке;
-
Status — текущий статус теста. Возможные варианты:
 — не выполнен;
— не выполнен; — вычисляется/еще не был запущен;
— вычисляется/еще не был запущен; — выполнен успешно;
— выполнен успешно; — вычисление закончилось по тайм-ауту.
— вычисление закончилось по тайм-ауту.
-
Last run date — дата последнего запуска теста (результат запуска в поле Status)
-
белая кнопка Выполнить — запустить выбранный тест в виде сессии:
-
Scenario — шаги теста;
-
Редактировать — изменить шаги теста, его окружение или название/персептрон;
-
История — история всех запусков данного теста. При нажатии на кнопку отображается следующая информация:
-
Date — дата и время запуска;
-
user — кто запускал тест;
-
totalTime — общее врем сессии;
-
status — статус выполнения теста.
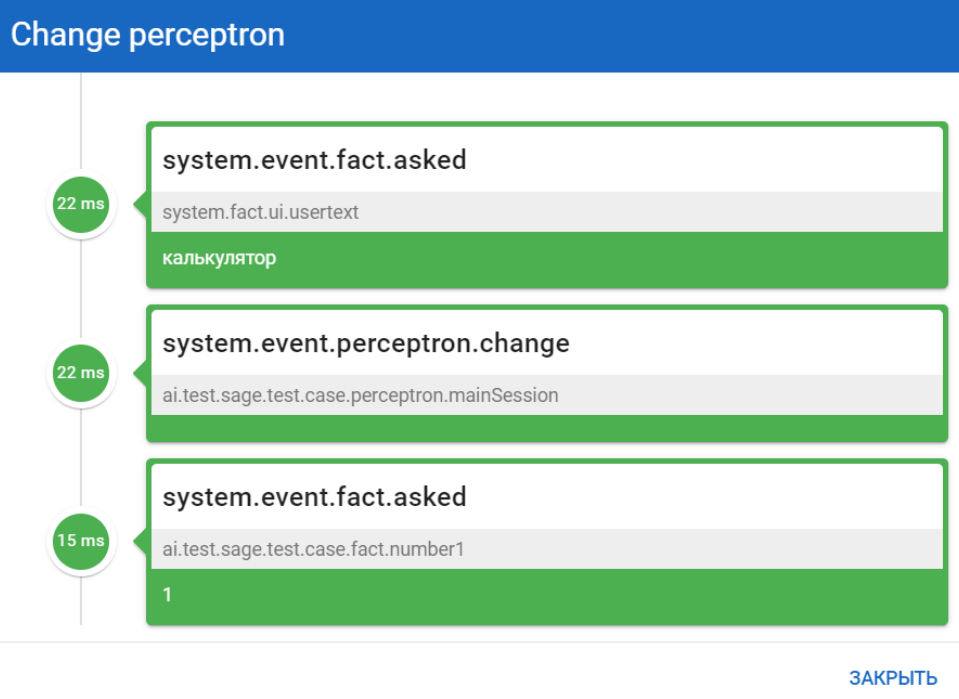
Чтобы просмотреть шаги сессии, нажмите на иконку
 .
. -
При нажатии на иконку отображаются детали тестовой сессии (шаги теста):
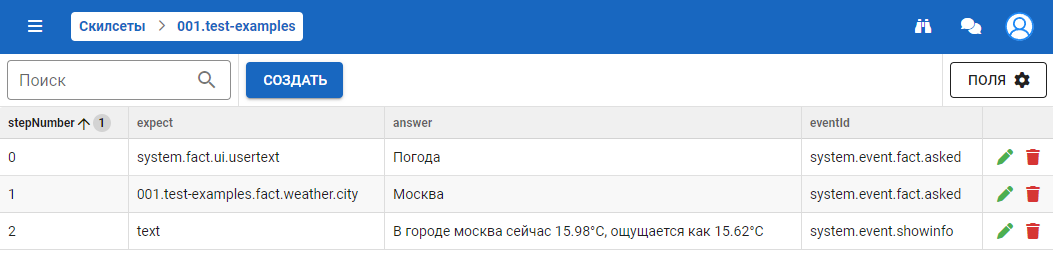
Создание теста
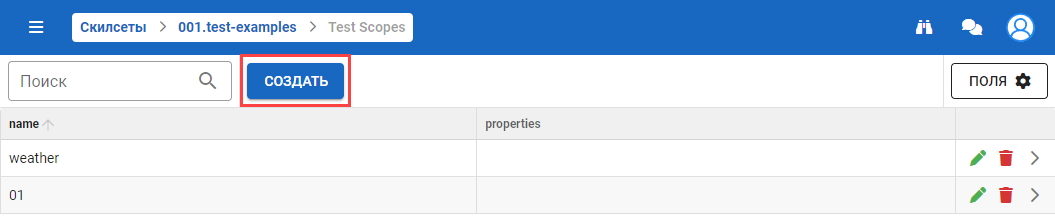
Перед созданием тестов необходимо создать папку для хранения тестов. Нажмите на кнопку Создать:
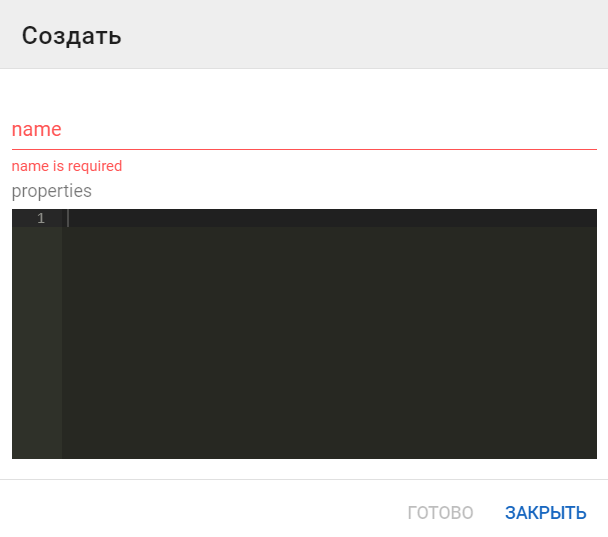
Заполните обязательные поля в отобразившейся форме и нажмите на кнопку Готово:
Или перейдите в ранее созданную папку с тестами и нажмите на кнопку Создать:
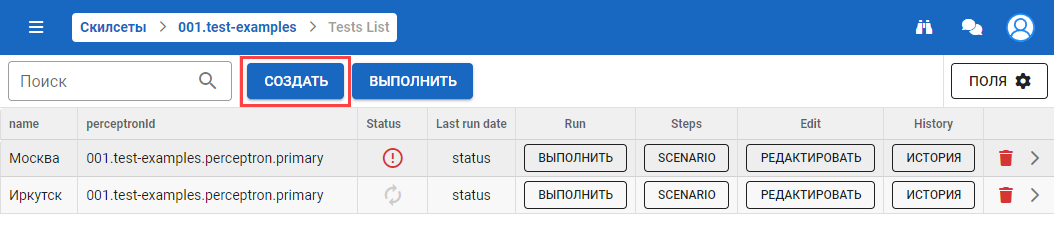
При создании теста нужно задать его название и указать персептрон, который необходимо тестировать:
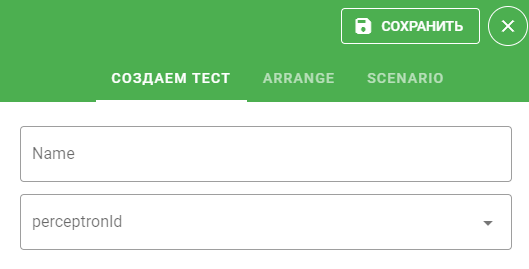
Окружение (контекст) сессии можно задать при помощи блока ARRANGE:
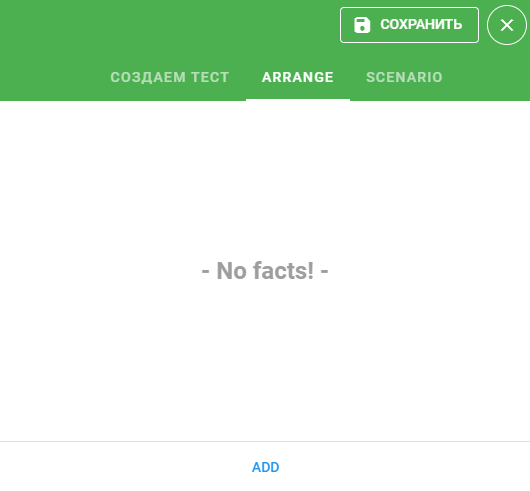
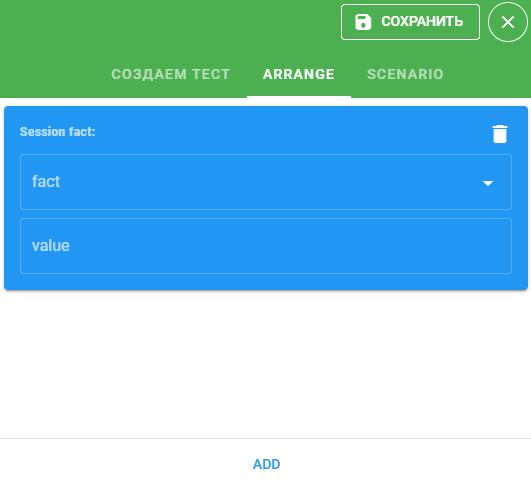
Нажали на кнопку Add:
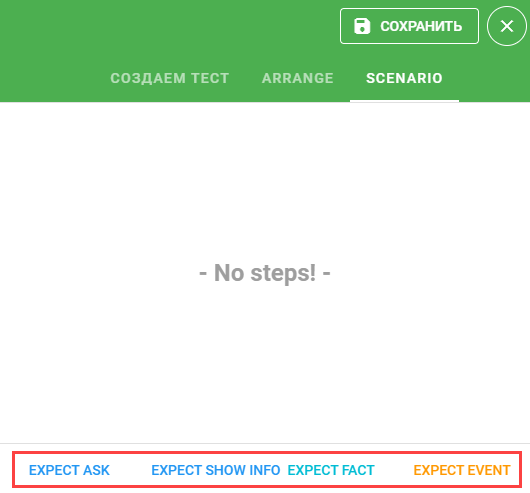
Шаги теста создаются в блоке SCENARIO. Чтобы создать шаг, нажмите на необходимый тип шага внизу формы:
Когда на форме появится шаг, нажмите иконку , чтобы перейти в режим редактирования:
, чтобы перейти в режим редактирования:
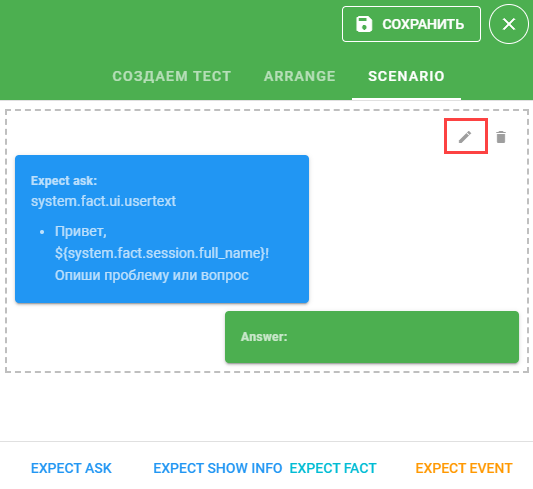
Доступные варианты шагов:
-
EXPECT ASK — ожидается, что система спросит факт у пользователя:
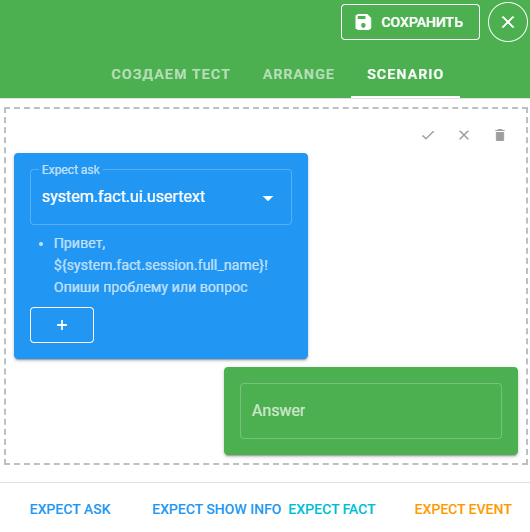
Нажмите на иконку
 , выберите необходимый факт. Укажите в поле Answer необходимое значение. Для сохранения нажмите на иконку
, выберите необходимый факт. Укажите в поле Answer необходимое значение. Для сохранения нажмите на иконку  .
. -
EXPECT SHOW INFO — ожидается информация для пользователя от системы:
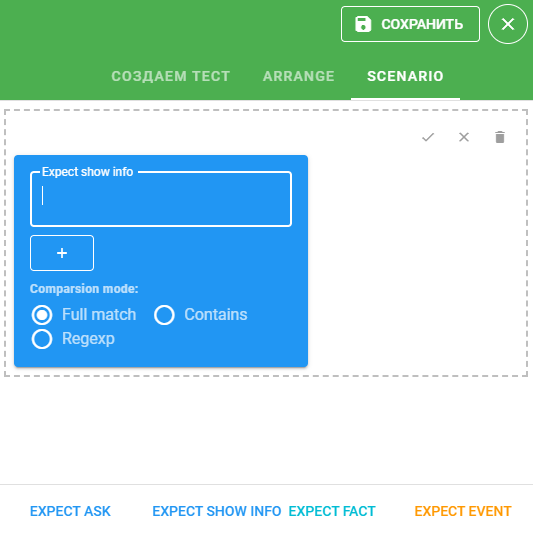
Укажите в поле Expect show info ожидаемое значение. Нажмите на кнопку
 , чтобы добавить значение и выберите необходимый способ сравнения: full match, contains или regexp.
, чтобы добавить значение и выберите необходимый способ сравнения: full match, contains или regexp. -
EXPECT FACT — ожидается, что факт примет определенное значение:
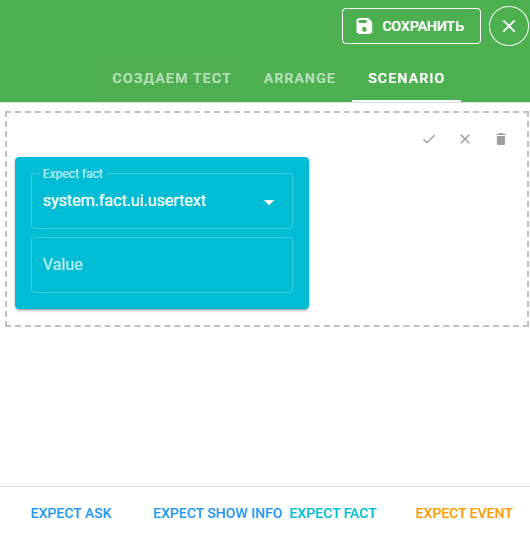
Выберите необходимое значение в поле Expect fact и укажите значение в поле Value.
-
EXPECT EVENT — ожидается определенное событие:
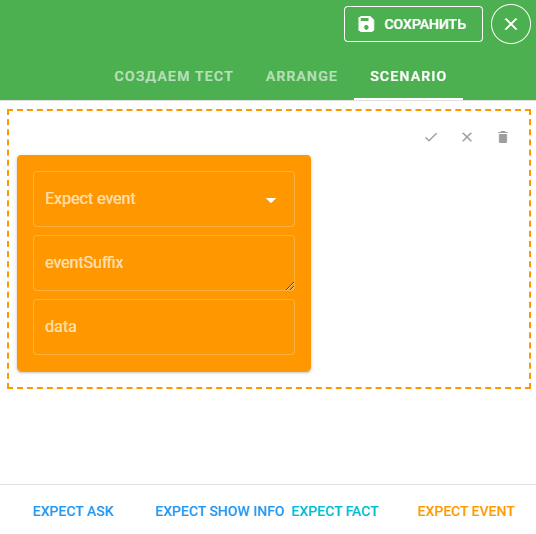
Выберите событие в поле Expect event, укажите id элемента в поле eventSuffix и укажите значение в поле data.
Агенты
Агент — это внутренняя или внешняя программа, которая запускается при возникновении события, на которое он подписан.
Чтобы просмотреть агенты скилсета нажмите на иконку :
В отобразившемся подразделе Инструменты выберите тип агента, с которым вы собираетесь работать:
- Researcher — исследует и возвращает Knowledge base или новые факты;
- Solver — исполняет действия в целевых системах и возвращает результаты работы в виде кода и варианта. Solver имеет возможность устанавливать Knowledge base и факты.
Агенты типов Researcher и Solver имеют идентичный интерфейс в административной панели. Рассмотрим его на примере списка агентов типа Researcher:
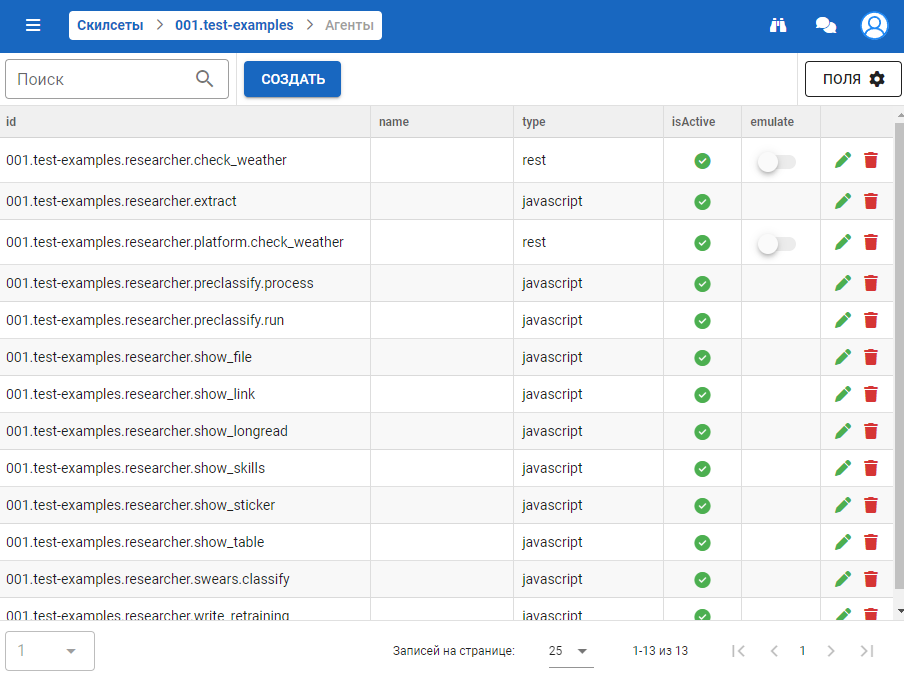
Чтобы создать новый агент, нажмите кнопку Создать:
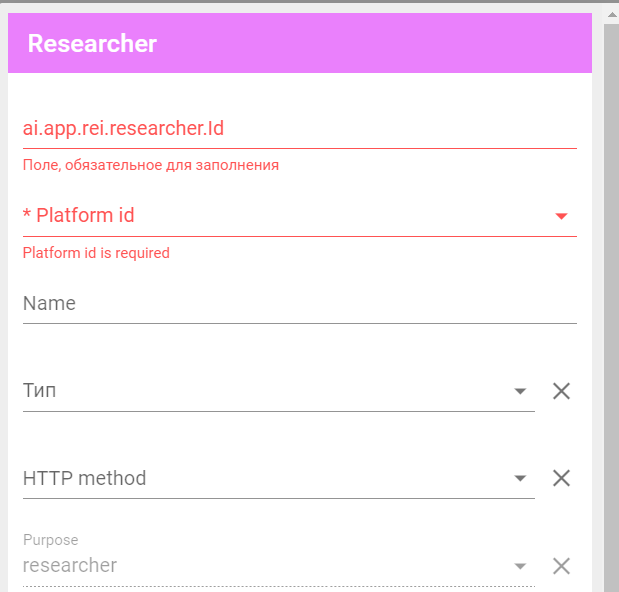
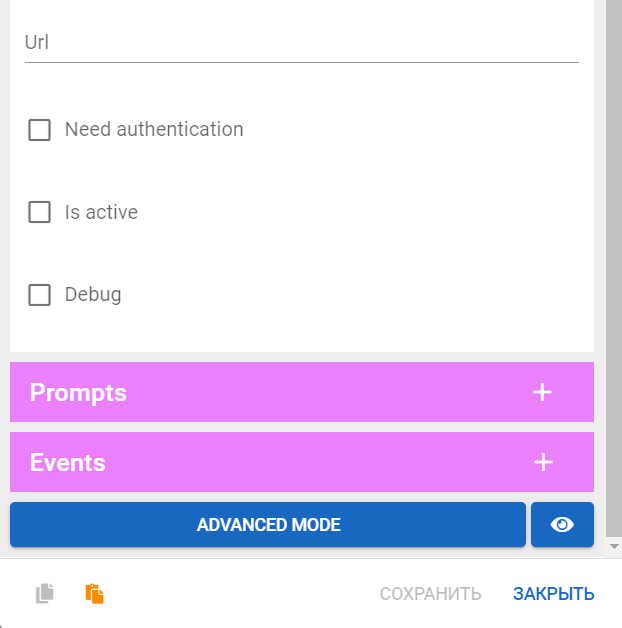
Параметры агента:
- id — уникальный идентификатор агента;
- Platform id — выбрать платформу, к которой будет обращаться агент при передаче данных из внутренней или внешней системы;
- Name — задать понятное имя на языке текущего сервера;
- Тип — выбрать необходимый тип используемого функционала агента:
- internal — системные агенты;
- remote — агенты с API доступом к сессии;
- javascript — внутренний агент;
- rest — подключение к API;
- sapodata — подключение к SAP-агенту.
- HTTP method — доступно три состояния (доступно во всех типах агентов кроме типа Javascript):
- get — ожидание данных от сервера;
- post — отправка данных на сервер;
- put — создание данных;
- patch — изменение данных (доступно только для REST агентов).
- Url — указывается ссылка на адрес сервера (доступно во всех типах агентов кроме типа JavaScript);
- Need authentication — агент запускается под учётной пользователя и требует логина в целевую систему;
- Is active — позволяет отключать и включать агента без его удаления;
- Debud — пишет в Pantani логи детали вызова;
- Prompts — сообщения от агента;
- Эмуляция — прописывается эмулирование ответа (доступно для типов агентов: remote, rest и sapodata);
- Events — прописываются все события, на которые должен быть подписан агент:
- Event id — идентификатор события;
- Event suffix — факт, который будет меняться;
- params.once — агент реагирует на данное событие, возникшее впервые. Возможные значения : true/false;
- params.sync — агент реагирует каждый раз при возникновении события. Возможные значения : true/false;
- params.keepOnChangeContext — агент реагирует на смену контента. Возможные значения : true/false;
- onlyForUiChannels — добавляются UI каналы, на которые необходимо подписываться. Если указан не валидный канал или канал не указан, то подписка не сработает.
После выбора Type появляются дополнительные блоки для ввода параметров:
- open Manifest для internal, remote, rest и sapodata;
- open Javascript для javascript и rest.

В Open Manifest прописывается тело запроса к API и указывается факт, в который нужно вернуть результат.
FAQs
Чтобы просмотреть FAQs скилсета нажмите на иконку :
В отобразившемся подразделе Инструменты выберите необходимый язык:
Часто задаваемые вопросы распределены по разделам. Внутри хранятся список вопросов (Questions) и список ответ (Answers).
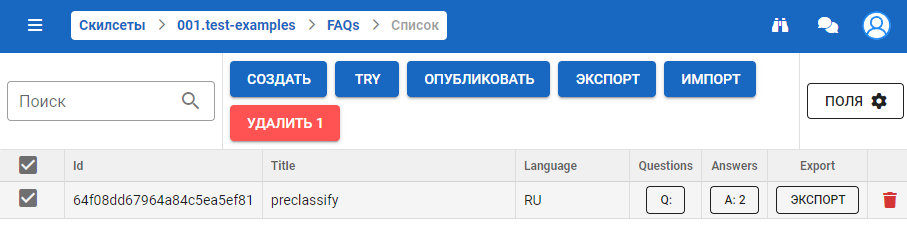
На экране доступны следующие элементы:
- строка поиска в правом верхнем углу — поиск FAQ.
- кнопка Создать — создание нового FAQ.
- кнопка Try — тестирование FAQ, внутренний инструмент, который разделяет датасет FAQs на несколько частей для проверки (тестирования) одной части с помощью другой.
- кнопка Опубликовать — публикация локального FAQ и one_to_one FAQ моделей (обучать one_to_one FAQ модель или нет — зависит от настройки конфигурационного файла faq_1t1_enabled).
- кнопка Экспорт — экспорт FAQ с вопросами и ответом в формате .csv или .xlsx.
- кнопка Импорт — импорт FAQ с вопросами и ответом в формате .csv или .xlsx.
- кнопка Удалить — удаление FAQ (необходимо сперва выбрать те FAQ, которые необходимо удалить). Также можно удалять FAQ по отдельности нажатием на иконку
- кнопки
 — переход к вопросам и ответам.
— переход к вопросам и ответам.
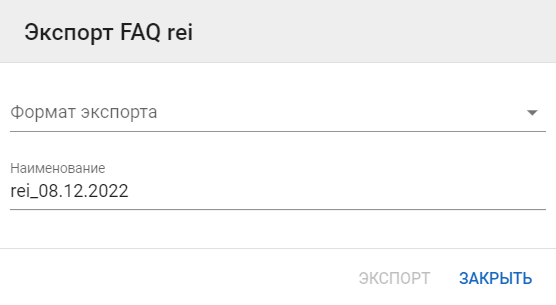
Экспорт FAQ
-
Выберите кнопку Экспорт напротив необходимой темы. Если необходимо экспортировать все FAQ, то можно нажать кнопку Экспорт наверху формы.
-
Выберите формат экспортируемого файла — .csv или .xlsx. Если выбран формат .csv, то необходимо также выбрать разделитель в поле Symbol.
-
Скорректировать наименование скачиваемого файла, при необходимости.
-
Нажать кнопку Экспорт:
Импорт FAQ
-
Нажмите на кнопку Импорт.
-
Переместите файл формата .csv или .xlsx для загрузки файла:
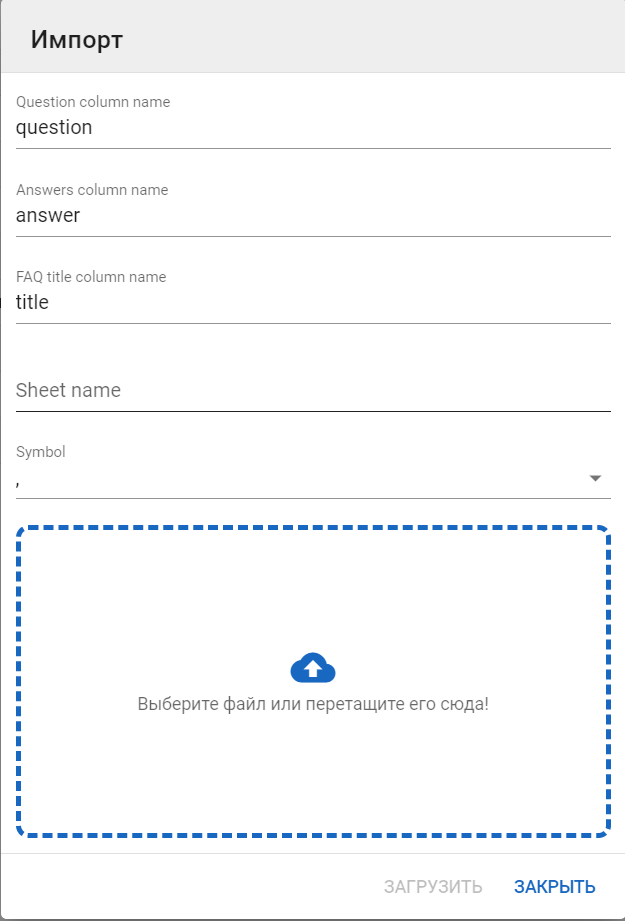
Значение полей:
- Question column name — указывается название столбца, откуда будут браться question (вопросы) для FAQ.
- Answers column name — указывается название столбца, откуда будут браться answers (ответы) для FAQ.
- FAQ title column name — указывается название столбца, откуда будет браться title для FAQ.
- Sheet name — используется для импорта в формате .xlsx для указания листа.
- Symbol — разделитель (необходимо указывать при импорте через формат .csv).
Работа с вопросами (Questions) и ответами (Answers)
Важно
После внесения изменений в вопросы (Questions) или ответы (Answers) необходимо сохранить изменения
Для просмотра вопросов и ответа по теме, выберите кнопку Questions или Answers из блока для перехода к деталям темы.
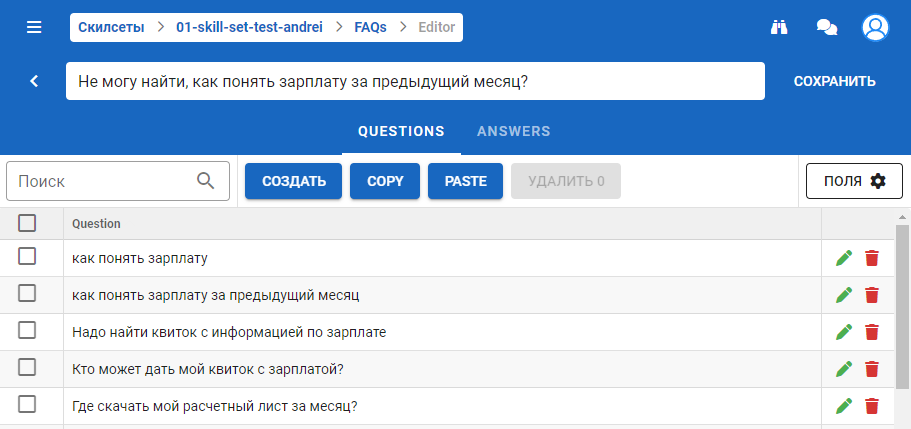
В блоке вопросов доступно:
- создание/добавление нового вопроса;
- поиск по вопросам;
- редактирование/удаление вопроса;
- копирование вопросов.
В блоке ответа доступно:
-
создание/добавление нового ответа;
-
редактирование/удаление ответа;
-
варианты действий для ответов:
- Show text — указывается текст;
- Show url — указывается ссылка (url), текст до ссылки (Before), текст после ссылки (After) и наименование ссылки (Title);
- Show document — указывается документ;
- Show Perceptron — указывается персептрон;
- Set Parameter — устанавливается факт и его значение;
- extract Пресет — извлекает значение их текста при помощи пресета;
- extract Модель — извлекает значение их текста при помощи модели;
- extract Экстрактор — извлекает значение их текста при помощи экстрактора.
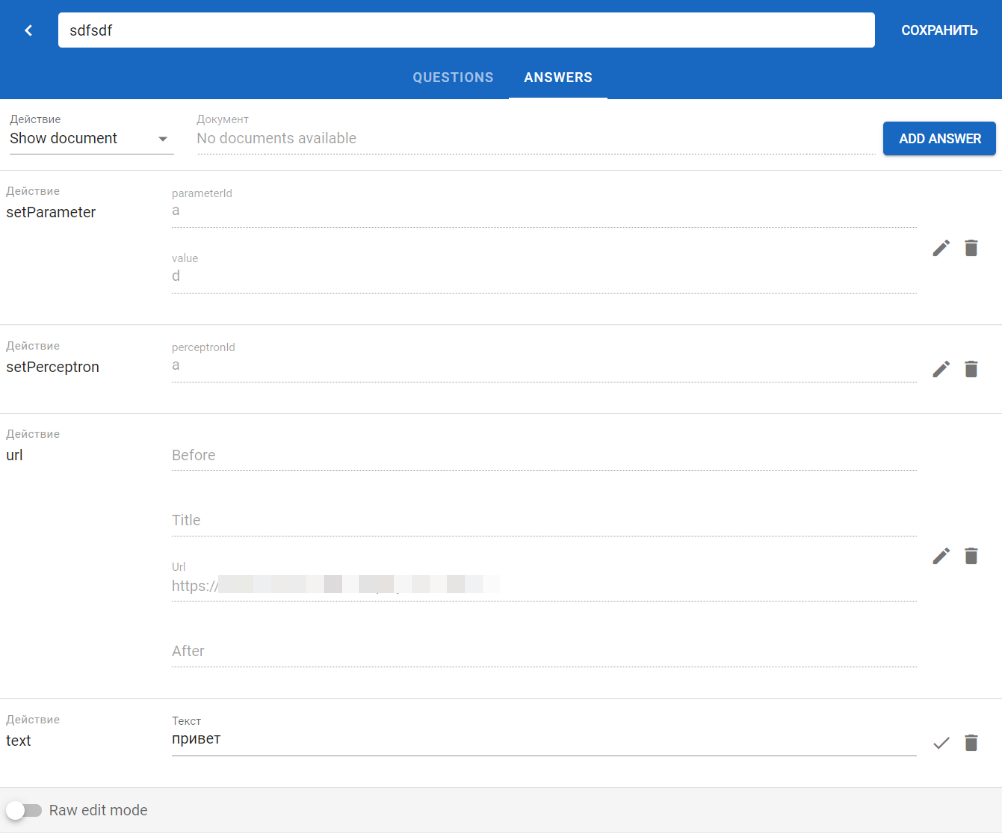
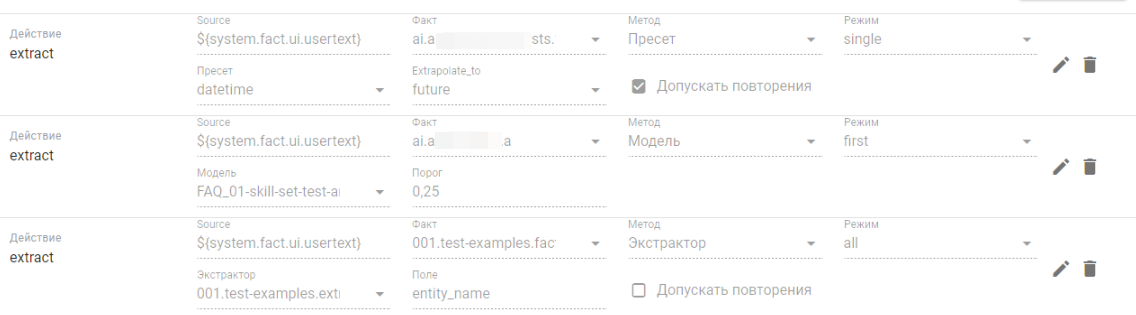
При редактировании доступен режим Raw edit mode. По окончании редактирования необходимо сохранить все изменения при помощи кнопки .
Публикация изменений FAQ
Важно
Глобальная и локальная FAQ модели создаются с настройками, которые указаны в конфиге faqDefaultPipeline.
Глобальная и локальная one_to_one FAQ модели создаются с настройками, которые указаны в конфиге faq_1t1_default_pipeline.
В глобальные FAQ модели не попадают скилсеты, у которых «включен» параметр excludeFaq (свойство скилсета).
По завершении работы с FAQ необходимо опубликовать изменения. Для этого выполните следующие шаги:
Шаг 1: В меню FAQ нажмите кнопку Опубликовать:
- Будет создана локальная NLP модель (в скилсете, в котором опубликовывался FAQ).
- Будет создан датасет, в который пойдет информация из всех FAQ, в котором опубликовывался FAQ.
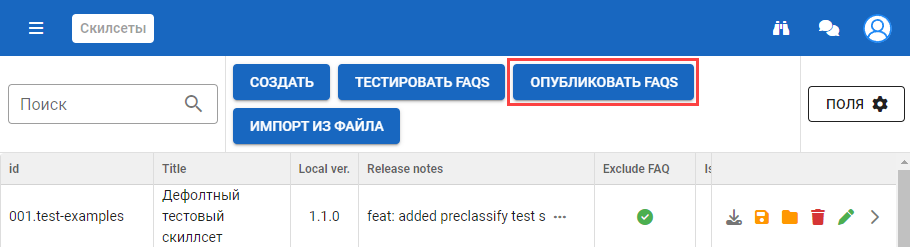
Шаг 2: На главной странице со списком скилсетов нажать кнопку Опубликовать FAQs.
- Глобальная FAQ модель будут сохранена или переобучена в скилсете, который записан в конфиге general_faq_skillset_idили в root.
- Датасет глобальной FAQ модели будет обновлен согласно значения FAQ.
Интерфейс публикации FAQ моделей
Форма публикации FAQ выглядит следующим образом (для случая, когда доступна публикация не только обычной FAQ, но и one_to_one):

Важно
Если основная FAQ модель не обучена, то невозможно обучить one_to_one модель.
В случае, если обычная FAQ модель обучена позже, чем one_to_one (т.е. велика вероятность, что модели обучены на разных датасетах), будет отображаться подсказка: «Необходимо переобучить модель».
One_to_one модель
Модель one-to-one может быть полезна, если каждый класс датасета достаточно узок и может иметь лишь малый набор возможных реплик. В таком случае можно вручную прописать все возможные реплики для каждого класса и обучить модель.
Как результат, будет получена модель, которая имеет 100% точность на тренировочной выборке, а так как «новых» реплик не предвидится (считается, что тренировочная выборка достаточна), то и в проде данная модель будет показывать идеальное качество и скорость работы.
На текущий момент one_to_one модель используется в паре с обычной FAQ моделью и обучается на её датасете. Обучать one_to_one модель или нет — задается через конфиг faq_1t1_enabled.
Пайплайн обучения one_to_one модели находится в конфиге faq_1t1_default_pipeline.
NLP модели
Чтобы просмотреть NLP модели скилсета нажмите на иконку :
В отобразившемся подразделе Инструменты выберите необходимый язык в блоке NLP модели:
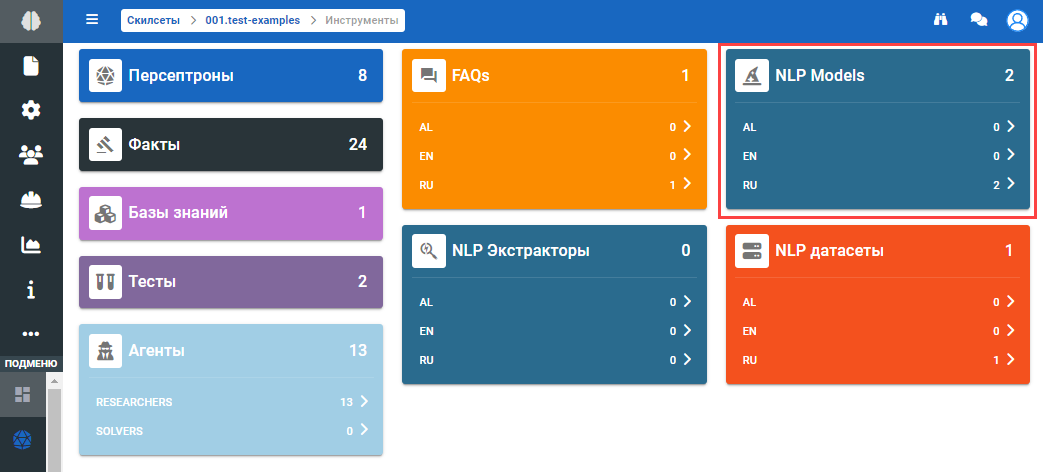
NLP модель — математический модуль, который использует датасет для классификации текста.
Для пользователя административной панели под словосочетанием «обучение NLP модели» подразумевается перенос и публикация обученной NLP модели на другую площадку (например, с площадки разработчика на тестовую площадку или с тестовой площадки на PROD) — кнопка Load для загрузки, кнопка Publish — для публикации. После публикации перенесенная рабочая модель готова к использованию.
Под словосочетанием «переобучение NLP модели» подразумевается повторное нажатие кнопки Publish со старым или новым датасетом на форме настройки NLP модели. Можно рассматривать этот процесс как обновление NLP-модели.
Примечание
Разработкой NLP-моделей занимаются NLP-разработчики, поэтому в этом блоке представлена ознакомительная информация.
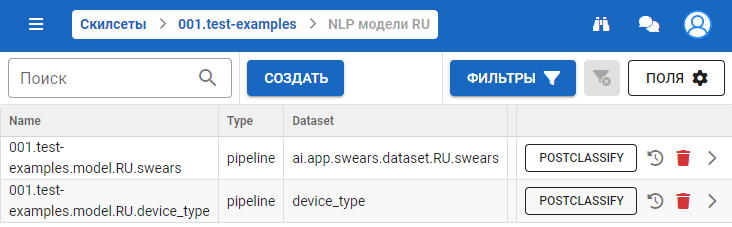
На главном экране доступны:
- поиск модели по названию;
- сортировка по методу анализа (классификации): pipeline, one_class, word2vec;
- сортировка по используемым датасетам, позволяет выбрать все модели, в которых используется данный датасет;
- postclassify — позволяет писать JS код, который после классификации может выполнять действия;
- статус модели (с возможностью обновить):
- успешный запрос статусов (* - статус отображается только в истории):
- not_found — таска (модель) с данным id не найдена в очереди;
- in_queue — таска в очереди (модель на очереди для обучения);
- started — таска выполняется (модель обучается);
- trained — таска завершена (модель обучена);
- failure — таска завершена из-за возникшей ошибке, не повлекшей завершение скрипта;
- revoked* — таска завершена по желанию пользователя (вызван /revoke для данной таски).
- ошибочный запрос статусов:
- instans_error — отправление некорректного запроса с фронта;
- error — вернулась ошибка при запросе статуса модели (код отличный от 2XX).
- успешный запрос статусов (* - статус отображается только в истории):
- история обучения модели;
- переход к деталям модели.
Чтобы перейти к деталям модели, нажмите на иконку .
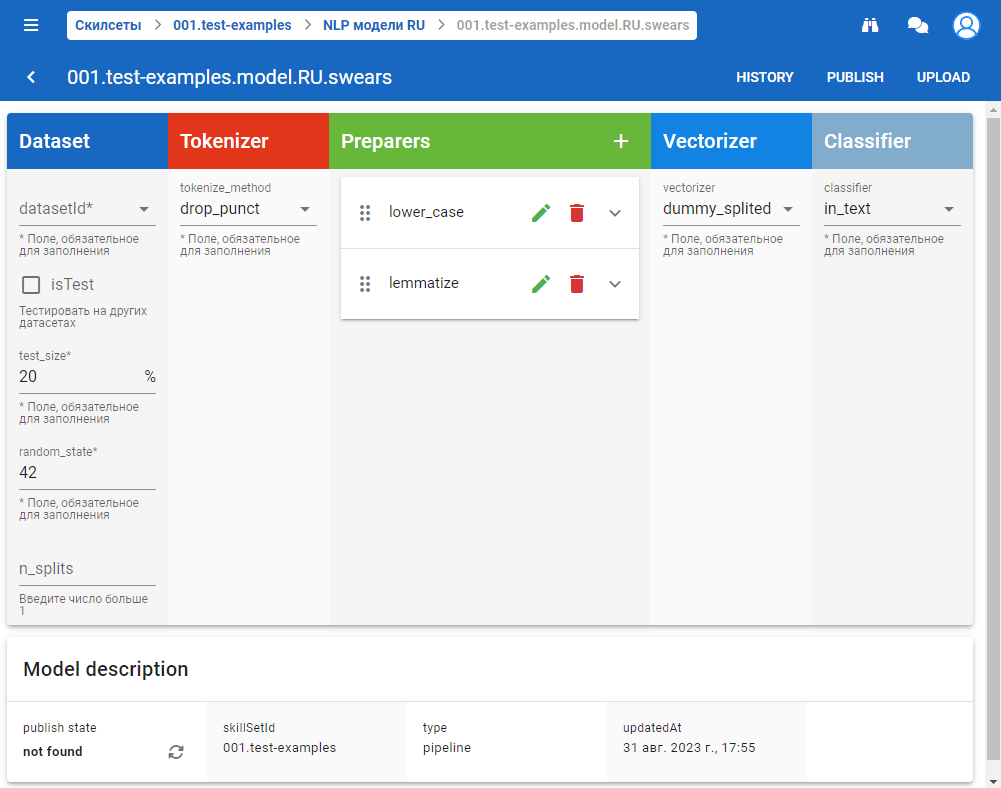
Меню модели находится в правом верхнем углу:
- кнопка History (история) — история публикации и тестирования модели.
- кнопка Classify (классифицировать) — рассчитать вероятность определения класса. Отображается, только если модель обучена.
- кнопка Test (тестировать) — тестирование модели. Отображается, только если модель обучена.
- кнопка Publish (публиковать) — обучить (опубликовать) модель.
- кнопки Dowload — скачать модель. Отображается, только если модель обучена.
- Upload — загрузить модель.
Важно
Обучение NLP модели — работа специалиста по Data Science, процедура которого не может быть рассмотрена в рамках функционала UI административной панели.
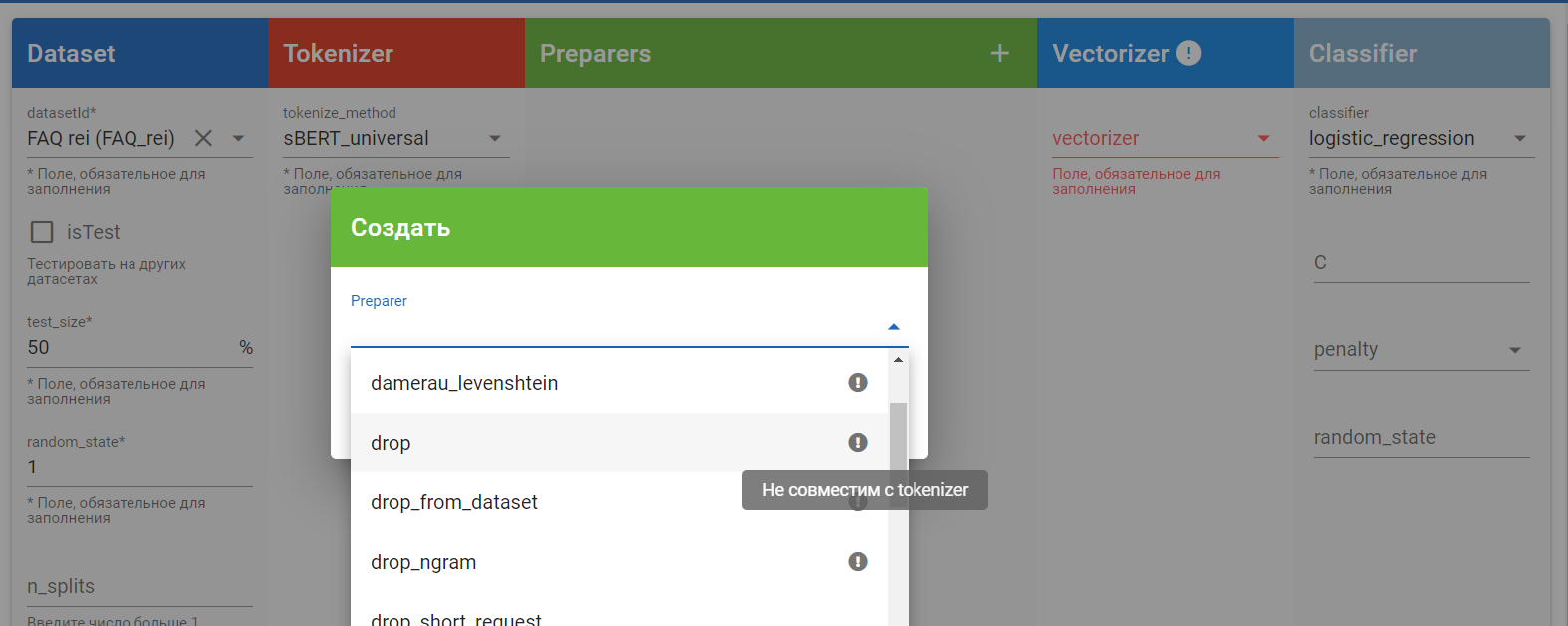
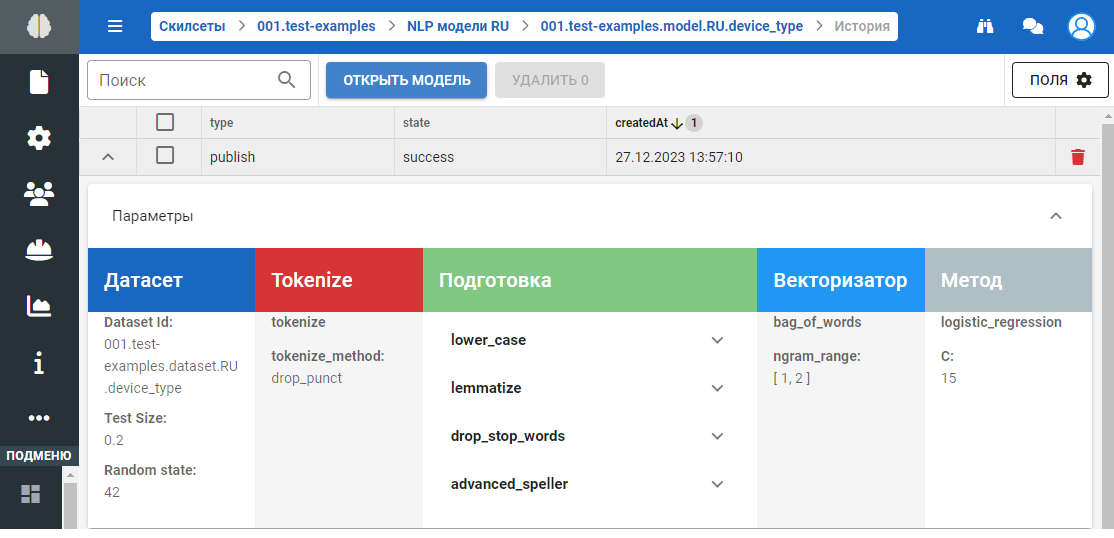
На данной форме при проведении настроек модели, например при добавлении Tokenizer, Preparers, Vectorizer и Classifier отображается дополнительная информация о совместимости сущностей. Например если мы добавили Tokenizer, а потом добавляем Preparers, то в списке будет отображаться восклицательный знак рядом с несовместимыми элементами.
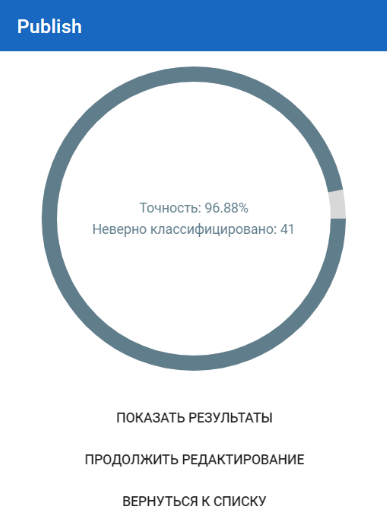
Публикация NLP модели
Используется для того, чтобы опубликовать модель. Результат публикации отображается на диаграмме (ниже на скриншоте видно, что модель обучилась с точностью 96.88%):
Classify (классификация NLP модели)
Используется для того, чтобы проверить текс на то, с какой вероятностью он принадлежит к каждому из классов.
Для этого нажмите на кнопку Classify, в появившемся окне введите слово или фразу, которые хотите проверить, и нажмите на кнопку Классифицировать:
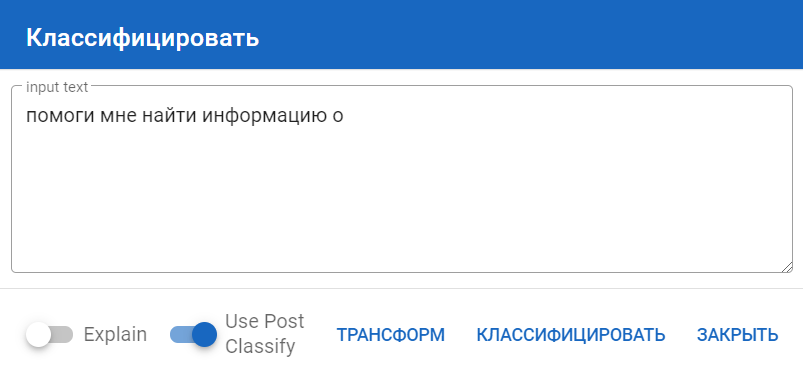
Результат обычной классификации:
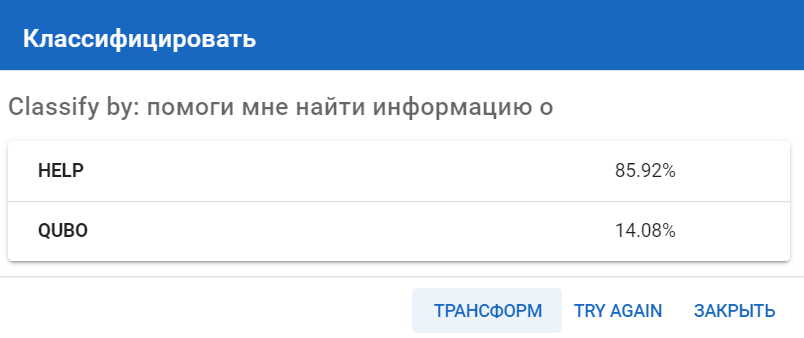
Классификация NLP модели с Explain
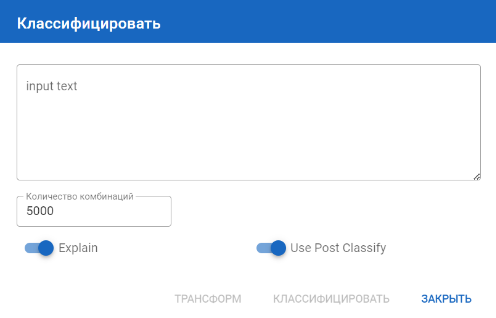
Также можно произвести классификацию с Explain (необходим для просмотра подробных результатов поиска в процентном отношении и по найденным словам, словосочетаниям). При такой классификации можно также изменить количество комбинаций, которые будут участвовать в классификации. По дефолту стоит значение 5000 (берется из конфига classify_explain_num_samples).
Результат классификации с Explain:
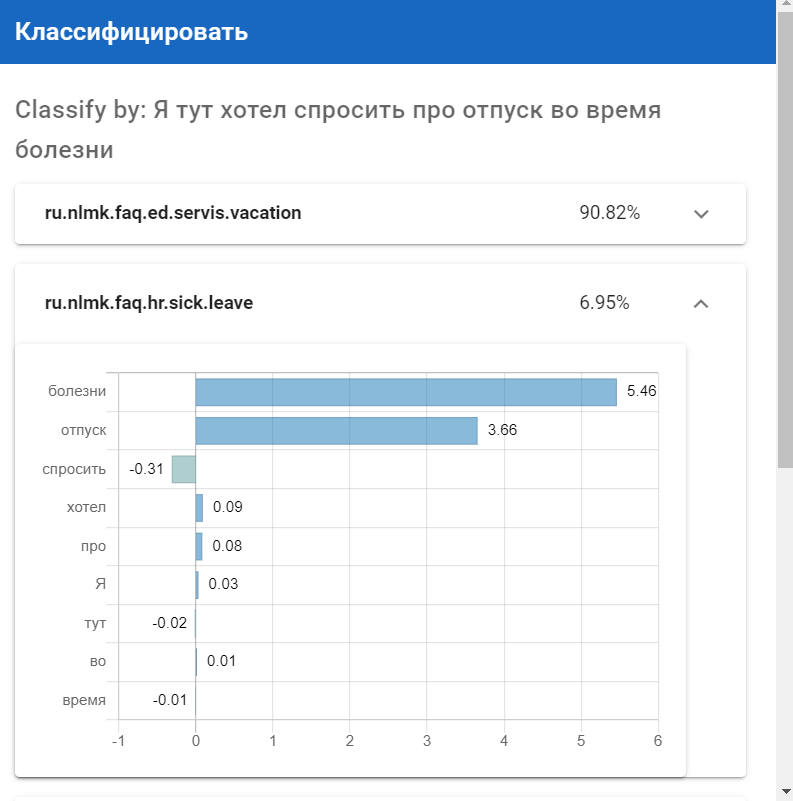
Эти графики помогают понять вклад токенов/слов в тот или иной класс:
- положительное значение — данное слово характерно для данного класса;
- отрицательное — характерно для прочих классов;
- около-нулевое значение — данное слово встречается как в текстах-представителях данного класса, так и в остальных текстах;
- итоговое число — это предсказание самого классификатора, коррелирует, но может не совпадать один-в-один с суммой вероятностей по отдельным словам, т.к. используются нелинейные функции в промежуточной модели, используемой при оценке важности отдельных слов (создается внутри интерпретатора при вызове explain()).
Графики по классам отображаются не на всех строках, а только на некоторых (определяется внутри ML параметром top_labels), исходя из следующей логики: берется не менее 2, но и не более 10 классов для объяснения, промежуточное значение может быть принято по критерию: top_labels = число классов, вероятность которых меньше вероятности TOP1 класса не более, чем на 0.1.
Например:
- классы получили вероятности: [0.1, 0.5, 0.6, 0.2]
top_labels = 2, т.к. максимальная вероятность 0.6 и лишь ДВА класса имеют отличие от 0.6 не более чем в 0.1 - классы получили вероятности: [0.1, 0.5, 0.6, 0.55]
top_labels = 3, т.к. максимальная вероятность 0.6 и лишь ТРИ класса имеют отличие от 0.6 не более чем в 0.1 - классы получили вероятности: [0.1, 0.5, 0.1, 0.2]
top_labels = 2, т.к. минимальное значение top_labels = 2
Трансформ NLP модели
Вывод обработанного текста после каждого препроцессинга.

Пока модель не опубликована, её не получится проклассифицировать.
Также при классификации можно посмотреть, каким образом менялся текст препроцессорами, и что именно ушло в модель для классификации (кнопка Трансформ).
Этап «__in_model_dictionary» оставляет в токенизированном тексте только те слова, которые имеются в словаре Vectorizer.
Тестирование NLP модели
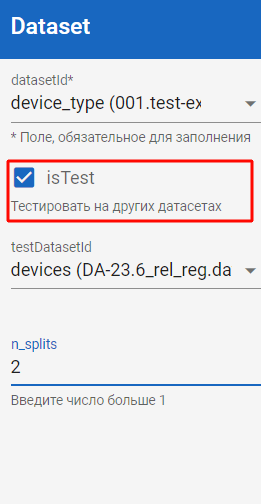
Используется для тестирования опубликованной модели при помощи другого датасета.
Для этого в блоке Dataset включите флаг isTest и выберите из выпадающего списка тестовый датасет, а затем нажмите кнопку Test в правом верхнем углу экрана.
Общий результат тестирования выводится в окне:
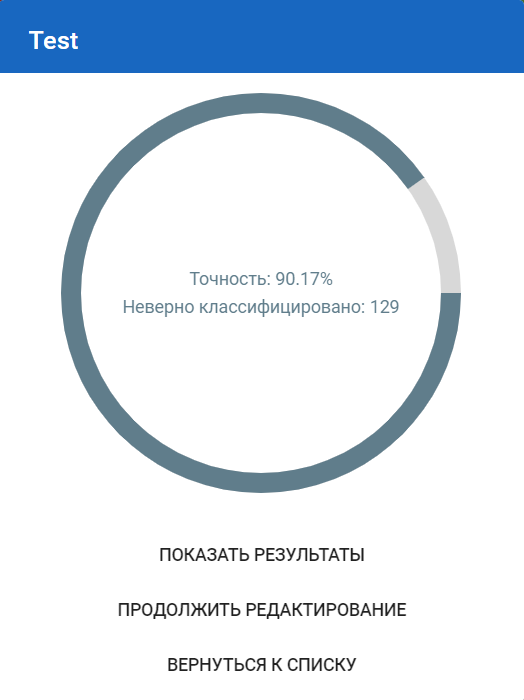
Чтобы просмотреть детали теста, нажмите кнопку Показать результаты в результатах теста и выберите тест для просмотра или выберите пункт History (История) в меню модели.
Загрузка NLP модели
Форма загрузки модели выглядит следующим образом:
Необходимо добавить модель (можно загружать только файл с форматом .zip) и нажать на кнопку Загрузить. После чего появится шкала выполнения процесса.
История NLP модели
В истории модели фиксируется информация о следующих событиях:
- publish — информация о процессе публикации модели;
- test — информация о тестировании модели на обученном датасете;
- test with «dataset» — информация о тестировании модели на произвольном датасете «dataset»;
- upload — информация о загрузке обученной модели.
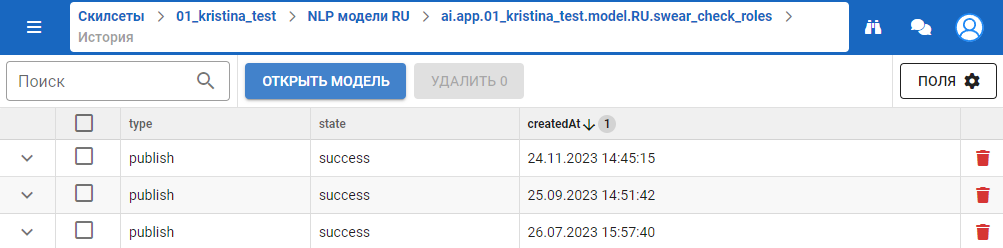
Чтобы просмотреть параметры тестирования, нажмите кнопку  в соответствующей строке.
в соответствующей строке.
В скрываемой панели Параметры находится информация о пайплайне NLP модели:
Вкладка «Точность»
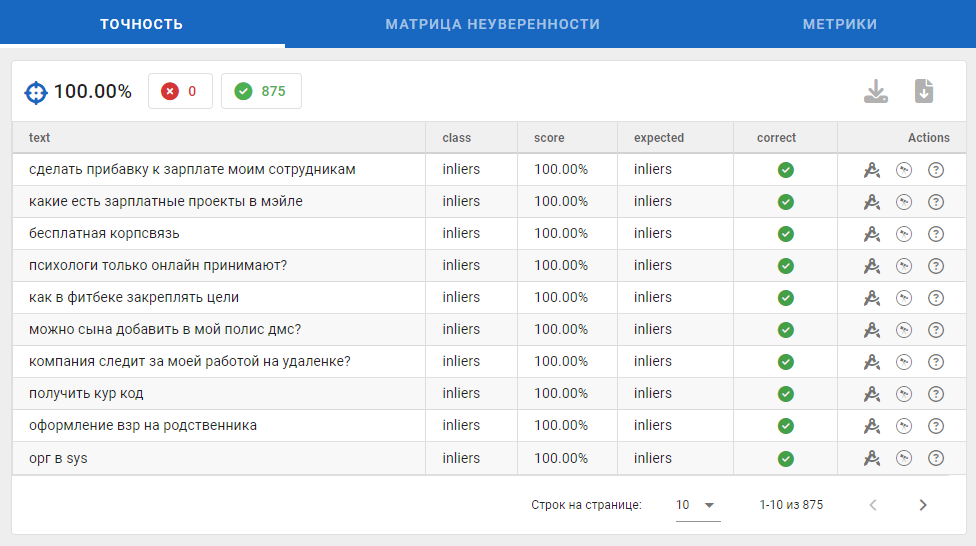
В истории могут присутствовать строки с пустыми полями class и score. Так получается из-за того, что в пайплайне классификации есть этап проверки «модель считает данный текст идентичным пустой строке?».
Данный этап помогает исключить вероятность не нулевого предсказания для текста, который «слишком не знаком для модели». Фактически, на этапе тестирования, модель рассчитывает метрики исходя из истинных N-классов и предсказанных N+1 классов (добавляется класс not_found_result).
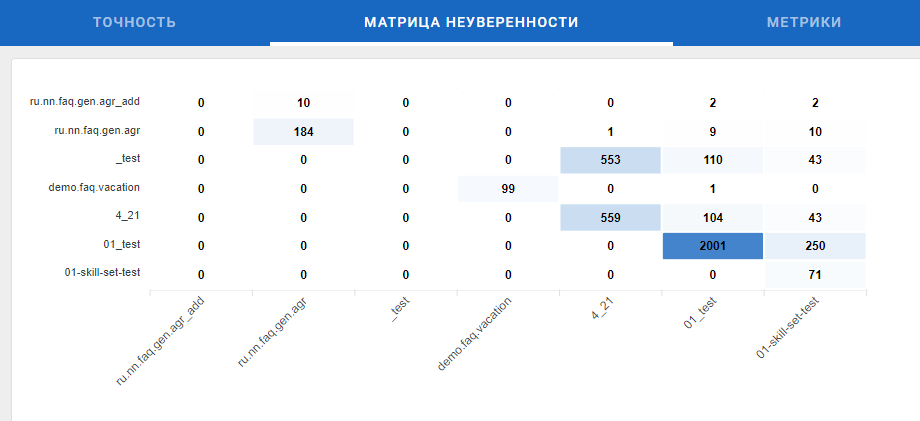
Вкладка «Матрица неуверенности»
Матрица неуверенности — таблица/матрица, которая позволяет визуализировать качество модели классификации путем сравнения предсказанного класса для фразы клиента с ее реальным классом.
Строки — предсказанные классы, столбцы — реальные. Числа в ячейках — количество соответствующих предсказаний.
Вкладка «Метрики»
- F-метрика — гармоническое среднее между точностью и полнотой. Формула: 2ТочностьПолнота / (Точность + Полнота).
- Полнота — это доля найденных классификатором примеров принадлежащих классу относительно всех примеров этого класса в тестовой выборке.
- Точность — это доля примеров, действительно принадлежащих определенному классу относительно всех примеров, которые модель отнесла к этому классу.
- ROC-кривая — показывает зависимость количества верно классифицированных положительных примеров от количества неверно классифицированных отрицательных примеров:
- micro — среднее арифметическое по всем примерам;
- macro — среднее значение средних арифметических по каждому классу;
- weighted — взвешенное macro, учитывающие количество примеров в каждом классе.
NLP датасеты
Чтобы просмотреть NLP датасеты скилсета нажмите на иконку :
В отобразившемся подразделе Инструменты выберите необходимый язык в блоке NLP датасеты:
Datasets — это размеченные по темам тексты пользователей, которые используются для обучения NLP моделей.
На главной странице Datasets доступны:
- поиск датасета;
- создание нового датасета;
- информация о датасете;
- режим редактирования папки;
- переход к деталям датасета.
Чтобы просмотреть детали датасета, нажмите на иконку .
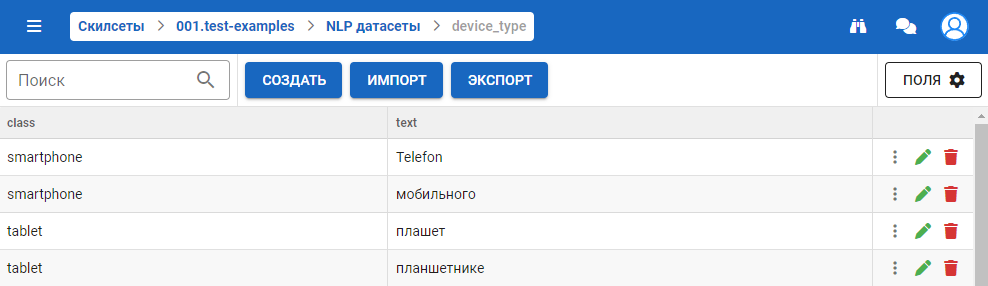
На форме с деталями датасета представлены следующая информация:
- Столбцы:
- class — класс, к которому относится текст.
- text — перечень текстов, которые относятся к определенным классам.
- Кнопки:
- Удалить класс — отображается при нажатии на иконку . Удаляет все записи в датасете, которые относятся к данному классу.
- Редактировать — открывает форму редактирования строки в датасете.
- Удалить — удаляет строку записи в датасете.
- Импорт — загружает содержимое датасета в формате .csv/ .xlsx.
- Экспорт — выгружает содержимое датасета в формате .csv/.xlsx.
- Удалить класс — отображается при нажатии на иконку
Создание датасета
-
Нажмите на кнопку Создать на главной странице с датасетами:
-
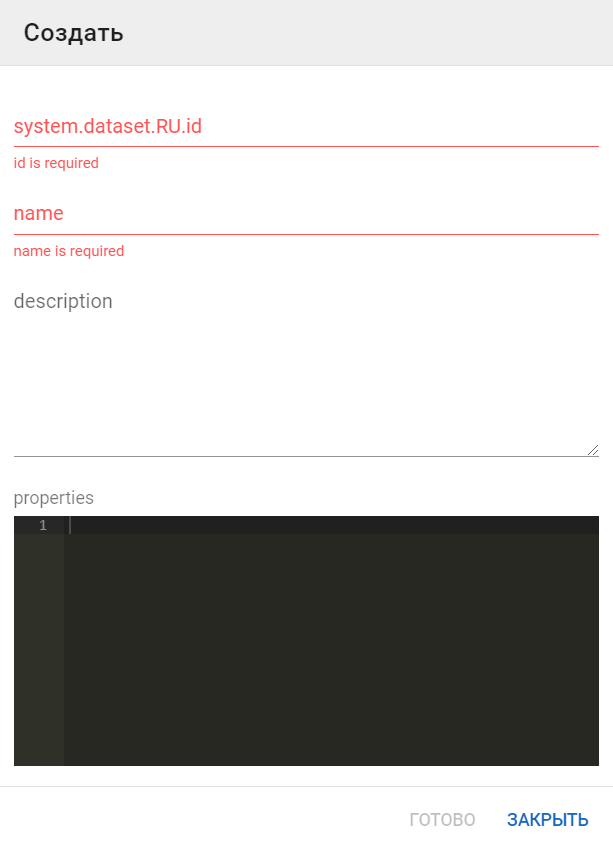
Укажите уникальный id и name. Описание (description) и свойства (properties) указывать необязательно.
Создание нового элемента датасета
Чтобы добавить новый элемент датасета:
-
Перейдите в детали датасета и нажмите на кнопку Создать:
-
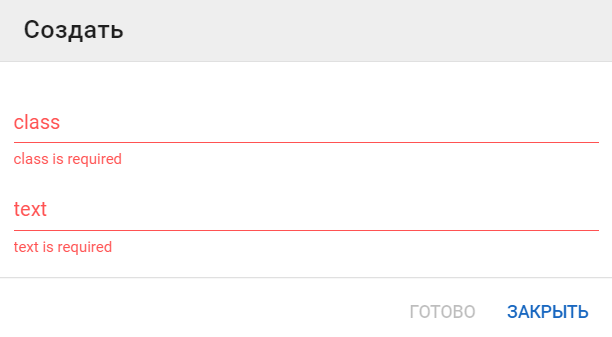
Укажите его класс и введите текст:
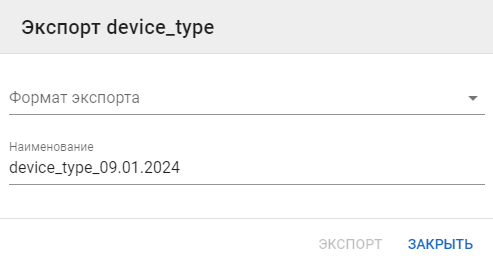
Экспорт датасета
-
Перейдите в детали датасета и нажмите на кнопку Экспорт.
-
Выберите формат экспортируемого датасета и при необходимости скорректируйте название файла:
-
Нажмите на кнопку Экспорт.
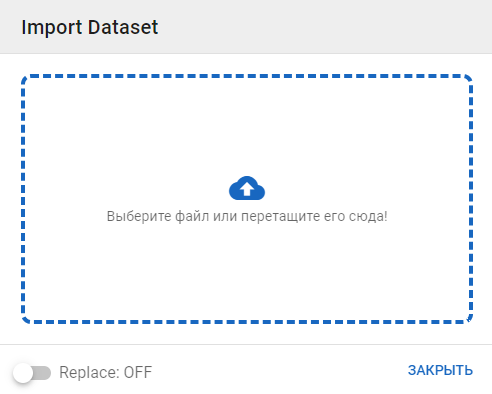
Импорт датасета
-
Перейдите в детали датасета и нажмите на кнопку Импорт.
-
Выберите файл для импорта. Можно выбрать только файл формата .csv (также необходимо выбрать разделитель) или .xlsx.
Требования к импортируемому файлу:
- Файл должен содержать текст и класс для каждого элемента датасета в формате "text","class".
- Текст обязательно должен быть на первом месте в строке.
- Текст и класс разделены запятой (для формата .csv). Для формата .xlsx значения находятся в разных столбцах.
-
Нажмите на кнопку Загрузить.
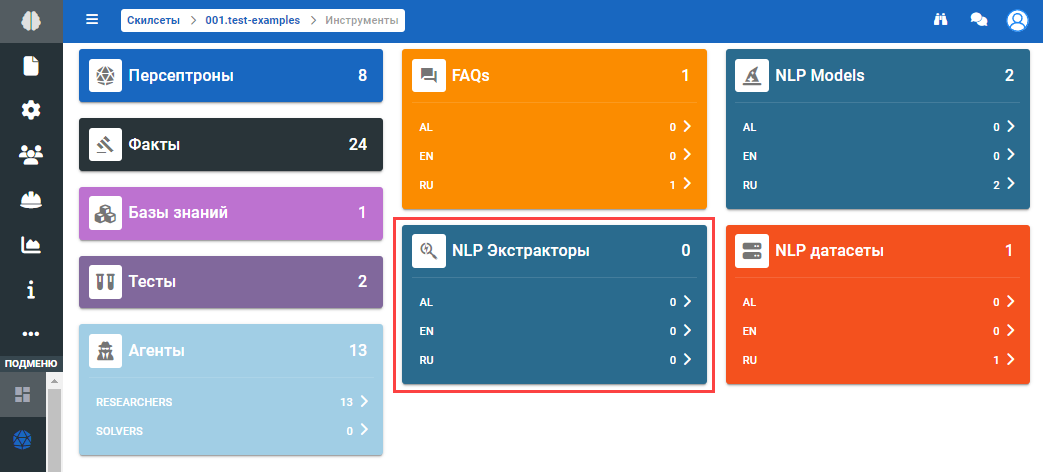
NLP экстракторы
Чтобы просмотреть NLP экстракторы скилсета нажмите на иконку :
В отобразившемся подразделе Инструменты выберите необходимый язык в блоке NLP экстракторы:
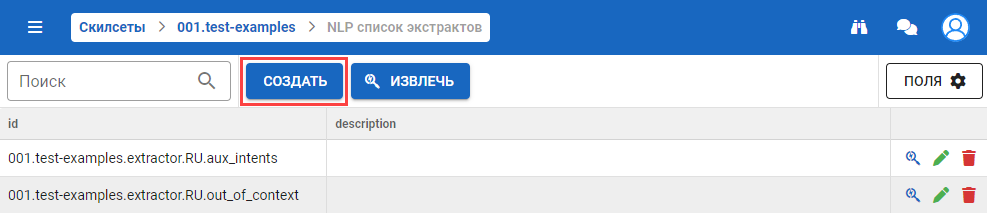
Создание экстрактора
-
Нажмите на кнопку Создать на странице с NLP экстракторами:
-
В отобразившемся окне:
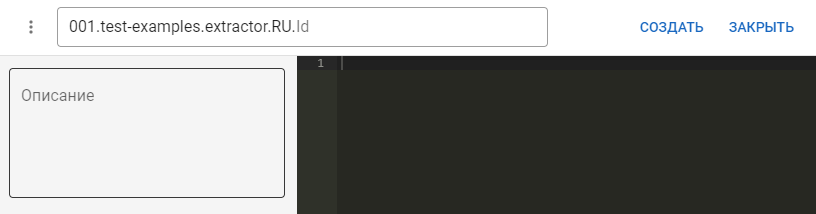
-
Задайте ID экстрактора. Используйте латинские буквы и разделительные символы. Указывайте понятный id, чтобы экстрактором могли воспользоваться без дополнительных пояснений.
-
Напишите тело экстрактора.
- Опишите цель и принцип работы экстрактора (необязательно).
- Сохраните экстрактор при помощи кнопки Создать.
-
-
Проверьте работу экстрактора:
-
Выберите кнопку Извлечь напротив нового экстрактора.
-
Введите текст, из которого необходимо извлечь факт и нажмите Извлечь:
-
Проверьте корректность работы экстрактора:
-
Сущность найдена при помощи экстрактора:

-
Сущность НЕ найдена при помощи экстрактора:
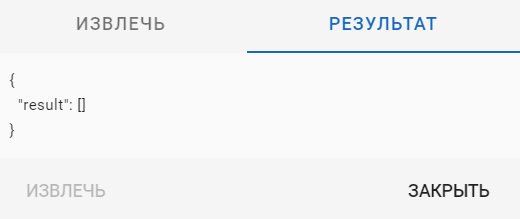
-
-
Документы (Documents)
Documents — это виртуальное хранилище, содержащее информацию обо всех документах, использующихся на текущем сервере.
Document имеет внутренний id, ссылается на определённое хранилище документов (платформу) с указанием id в данной платформе. Также указывается заголовок (как будет отображаться документ в диалоге) и имя файла (может совпадать с оригинальным или нет).
Важно
Documents хранит только информацию о документах, а именно:
- название и уникальный id документа;
- тип платформы и название платформы размещения документа;
- локализацию (зависимость от языка);
- имя файла на платформе размещения;
- ссылку на документ на платформе размещения.
Раздел Документы состоит из следующих подразделов:
- Список — список записей о документах;
- Типы источников — список типов платформ размещения документов;
- Источники — список платформ размещения документов.
Список
Чтобы найти документ, используйте строку поиска.
Поиск осуществляется по названию (name), id, имени файла (fileName) и ссылке на документ на платформе размещения (pathInSource).
Элементы управления документами позволяют:
-
создать новую запись о документе при помощи кнопки Создать. В открывшейся форме красным отмечены обязательные для заполнения поля:
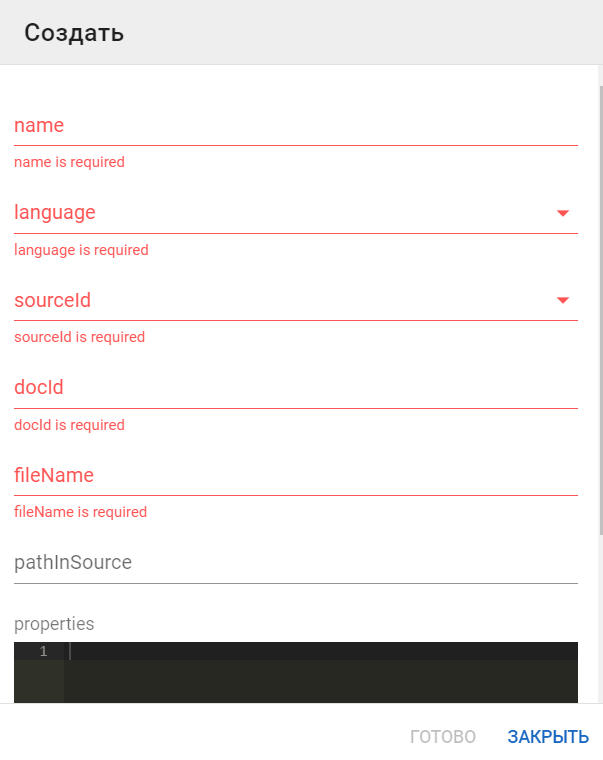
-
импортировать записи о документах в форме таблицы XLSX;
- экспортировать все доступные записи о документах в форме таблицы XLSX с целью переноса на другой сервер;
- удалить запись о документе;
- редактировать запись об одном документе.
Чтобы удалить все записи о документах на странице, нажмите на пустое поле слева от блока name. На верней панели управления станет доступна кнопка Удалить.
Список записей о документах возможно отсортировать при помощи кнопки Фильтры:
- по языку;
- по платформе размещения документа.
Типы источников
Платформа может оперировать документами многих хранилищ. Хранилища документов могут быть нескольких типов. Соответствующий раздел меню позволяет настроить типы хранилищ. Система использует в качестве хранилищ внутренние и внешние платформы:
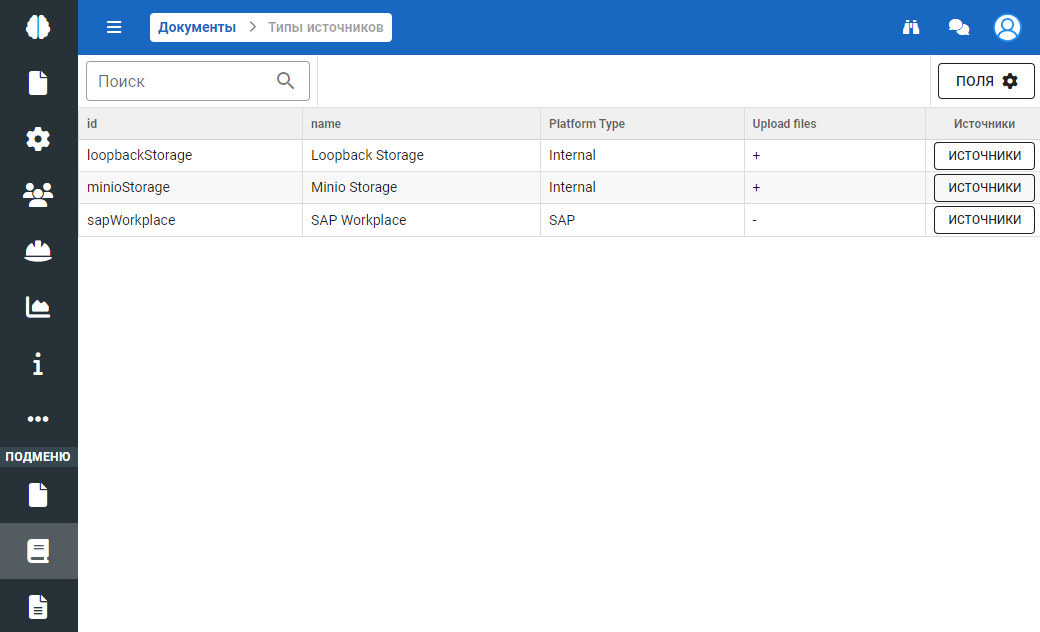
Внутренние хранилища (internal) позволяют как загружать, так и выгружать документы. К внутренним хранилищам системы относятся Loopback Storage и MinIO Storage.
Внешние хранилища позволяют только выгружать документы. В качестве внешнего хранилища система использует сервис SAP.
Настройки
Раздел Настройки позволяет управлять основными настройками системы. Подраздел блока Настройки обеспечивает быстрый доступ к настройкам.
Раздел содержит следующие подразделы:
- Конфигурации — конфигурационные параметры выполнения процессов текущего сервера.
- Целевые системы — типы платформ агентов, используемые на текущем сервере.
- Язык — настройка языковой зависимости текущего сервера.
- Операции — список системных и кастомных операций, используемых в скилсетах текущего сервера.
- Preclassify — список настраиваемых правил безусловного перехода в какую-либо область умений / сценарий.
- Системные агенты — системные агенты (программы), обеспечивающие ход диалога.
- Подписки агентов — содержит все подписки агентов инстанса, для удобства работы.
- Стартовые умения — область описания и установки базовых умений и инструментов системы.
- NLP модели — содержит список всех NLP моделей системы с возможность запустить процесс миграции.
Конфигурации
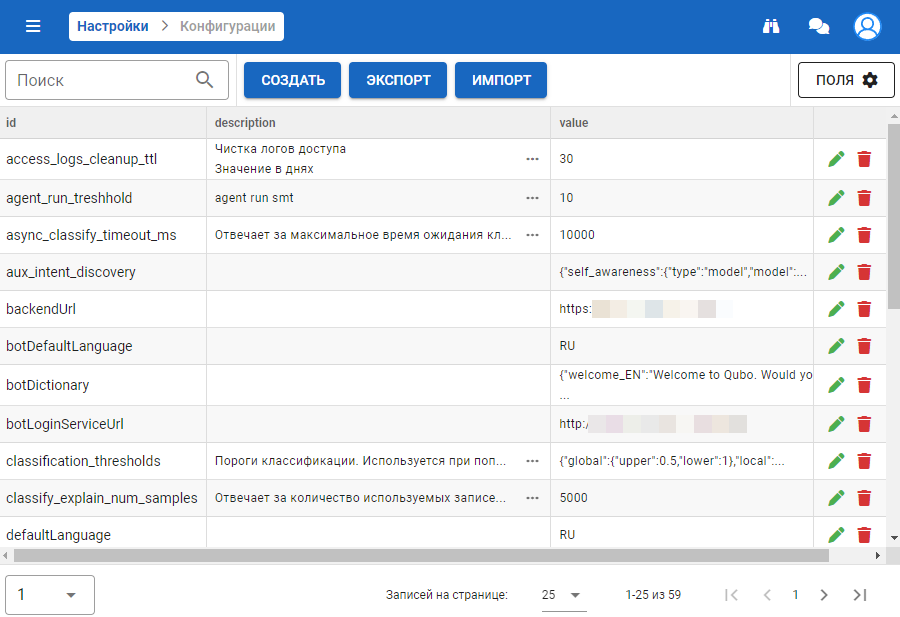
Множество конфигурационных элементов вынесено из кода внутренних и функциональных агентов для возможности быстрой подстройки определённых свойств без изменения программного кода. Таймаут, адрес некоторого общего сервиса и т.п. — примеры таких конфигурационных параметров. Управление ими вынесено в отдельный раздел меню.
Администратор системы может изменять значения существующих параметров, добавлять новые и т.д.
Импорт и экспорт конфигов
Для того, чтобы выгрузить конфиги инстанса или загрузить новые конфиги, используйте кнопки Импорт и Экспорт над списком конфигов. Формат — JSON.
Важно
Если импортируемый конфиг уже существует, система перепишет его значение.
Конфиг состоит из следующих параметров:
- id — идентификатор конфига;
- description — описание конфига, для чего он нужен;
- type of editor — отвечает за тип редактора для поля value;
- json — редактор JSON;
- text — текстовое поле;
- value — вписывается значение конфига.
Целевые системы
Целевые системы — это типы платформ, которые используются на текущем сервере.
Платформа является средой работы агента, программы, написанной на языке JavaScript и выполняющей определенную операцию в рамках платформы. Если пользователю не присвоен тип платформы, то использование агентов этой платформы невозможно.
Ниже представлены примеры платформ по одному из проектов. Данные платформы не ограничивают сервисы, с которым система может интегрироваться, а приведены в качестве примера:
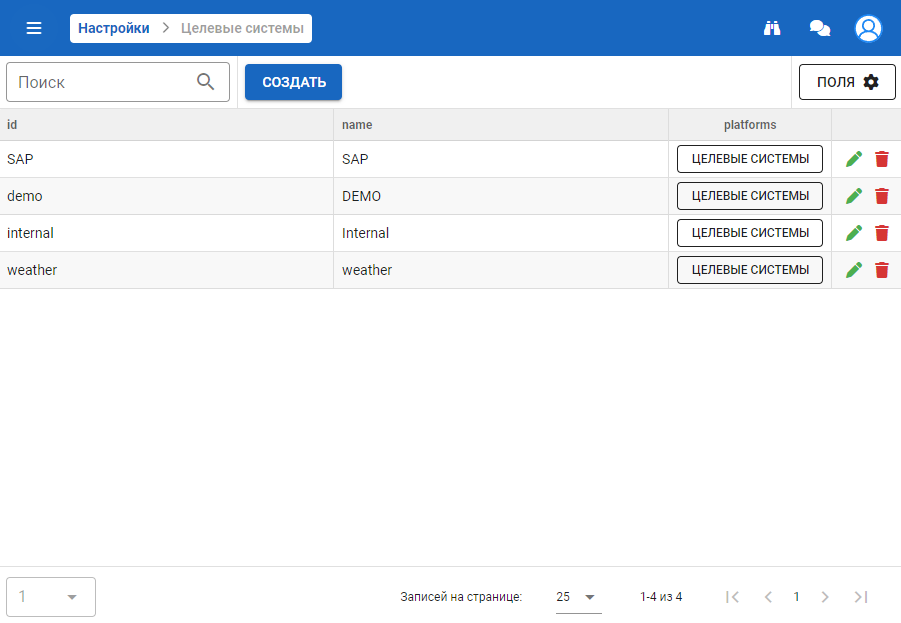
Присутствуют системы:
- Internal — внутренняя платформа, в рамках которой действуют все системные агенты, отвечающие ход сессии. Если пользователю не присвоена платформа internal, то сессия не стартует.
- SAP — одна из целевых систем клиента, из которой система может получать информацию для диалогов.
- DS — сервис хранения и управления информации, касающейся аутентификации пользователей.
Список может быть дополнен практически любой системой.
Язык
Раздел с языками данного сервера. На текущий момент интерфейс поддерживает два языка: RU (дефолтный) и EN.
Операции
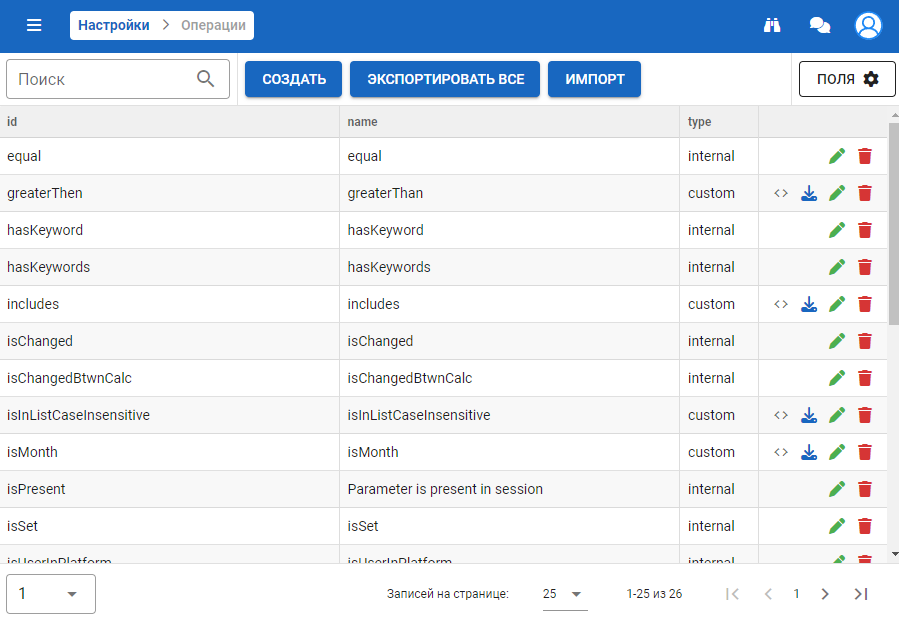
На данной форме отображается список операций, используемых разработчиками сценариев для связи элементов персептрона.
Существует два типа операций:
-
internal — системные операции;
-
custom — кастомные операции.
Также на форме доступен инструмент по созданию, экспорту и импорту custom операций.
Важно
Операции с типом internal нельзя создавать, экспортировать и импортировать.
Preclassify
Это настраиваемые правила безусловного перехода в какую-либо область умений / сценарий.
Правила состоят из:
- операции (любой операции, которая есть на данном стенде);
- аргументов данной операции;
- результата (реакции), это может быть:
- определение области знаний, т.е. скилсет, и темы, т.е. элемент FAQ в этом скилсете (второе опционально);
- указание какого-либо конкретного персептрона.
Правило считается сработавшим, если указанная операция, получившая на вход аргументы из самого правила и текст пользователя (вместо обычно получаемого значения факта), вернула true. Правила проверяются по порядку, первое сработавшее правило и считается финальным результатом.
Могут быть использованы для настройки фиксированных жёстких переходов по какой-то конкретной фразе / слову. Иногда эффективны, как быстрое временное решение или как закрытие каких-то нюансов / недочётов классификации.
Также настраиваемые наборы правил могут быть разными в зависимости от языка, так же, как, например, модели / датасеты / экстракторы.
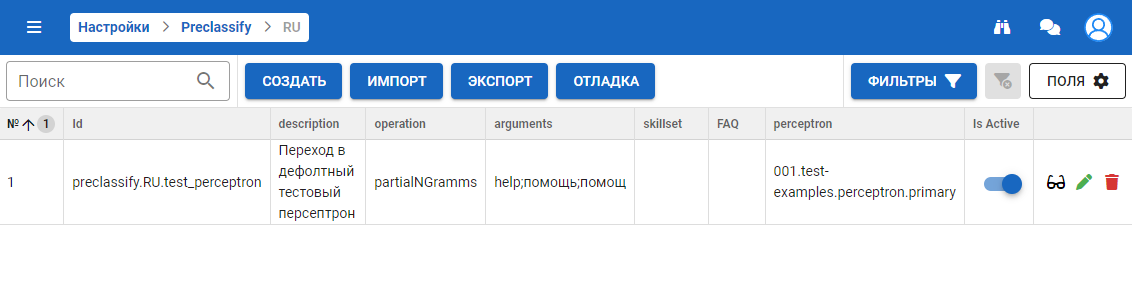
На форме присутствуют следующие элементы:
- Кнопка Создать — создание правила для конкретного языка (на макете находимся в разделе RU).
- Кнопка Импорт — импорт правил конкретного языка.
- Кнопка Экспорт — экспорт правил конкретного языка.
- Кнопка Отладка — отладка всех правил в порядковом номере. Возвращается результат первого сработавшего.
- Фильтры и сброс фильтров — работы с фильтрами для списка.
- Строка правила:
- Is Active — отключение/включение правила.
- Отладка preclassify — отладка конкретного правила.
- Редактирование — редактирование правила.
- Удаление — удаление правила.
Системные агенты
Системные агенты — это список агентов, которые обеспечивают работоспособность всех процессов, происходящих в диалоге.
Подписки агентов
На данной форме видны все подписки агентов на данном инстансе.
Также можно править существующие, удалять и создавать новые подписки.
Важно
Если подключен репозиторий, то для правки подписки или создания новой, необходимо, чтобы скилсет, в котором находится агент, был в работе.
На форме доступна фильтрация по полям, сброс фильтров, а также есть возможность перейти в скилсет, в котором находится агент.
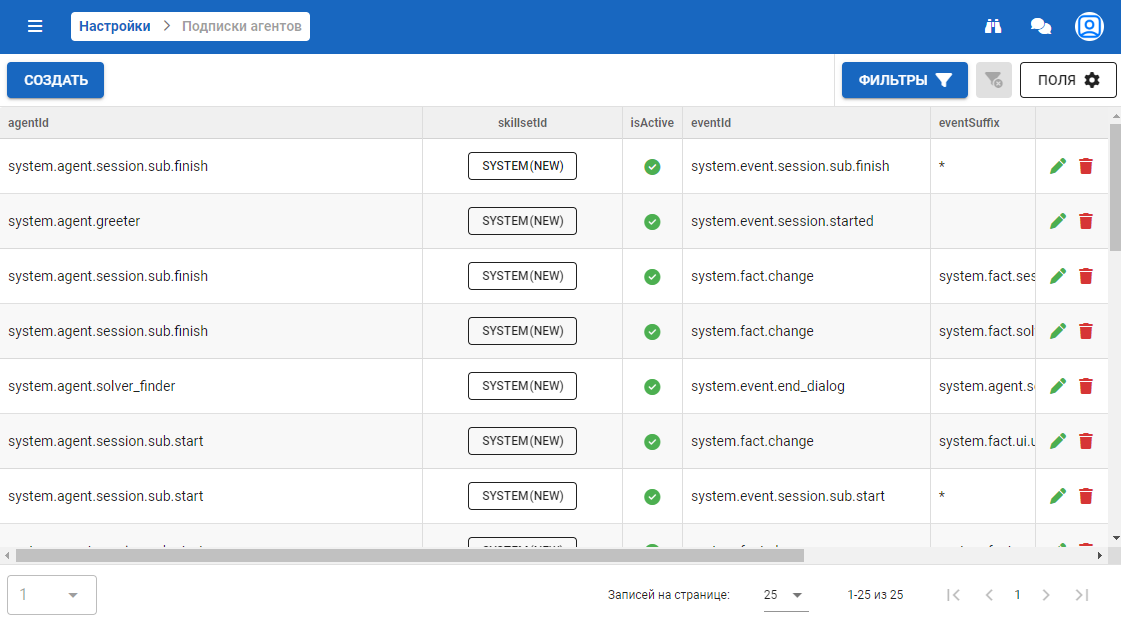
Форма создания подписки состоит из следующих полей:
- agentId — идентификатор агента;
- eventId — идентификатор события (например: system.fact.change)
- eventSuffix — конкретика по событию, при возникновении которого срабатывает агент:
- подписка на system.fact.change:* запускает подписанного агента при изменении любого факта;
- подписка на system.fact.change:fact1 запускает подписанного агента при изменении факта fact1;
- params.sync — агент реагирует каждый раз при возникновении события. Возможные значения : true/false;
- params.once — агент реагирует на данное событие, возникшее впервые. Возможные значения : true/false;
- params.keepOnChangeContext — агент реагирует на смену контента. Возможные значения : true/false;
- onlyForUiChannels — добавляются UI каналы, на которые необходимо подписываться. Если указан не валидный канал или канал не указан, то подписка не сработает.
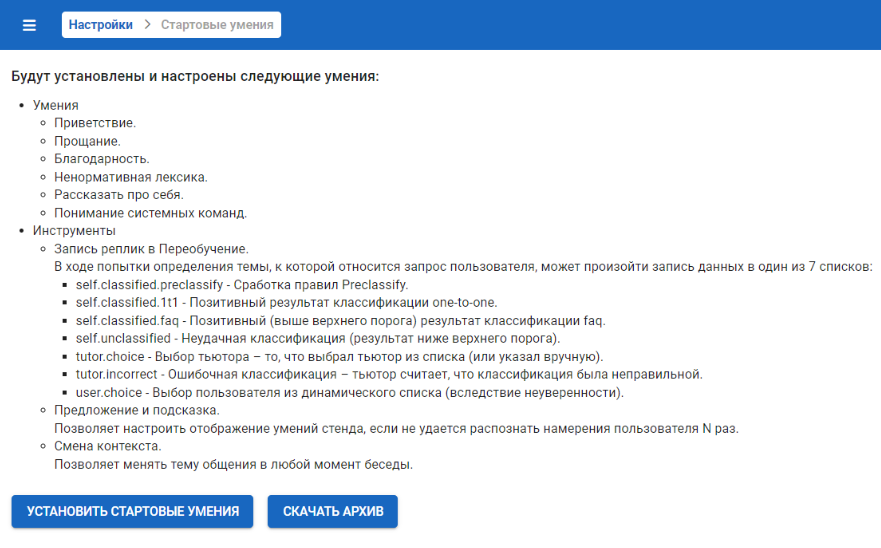
Стартовые умения
В данном подразделе находится описание стартовых умений и инструментов системы, которые можно установить или скачать.
Функцией по установке можно пользоваться на новых стендах, где нет пока никаких скилсетов, кроме системного, чтобы система обучилась стартовым умениям.
Если начать установку на стенд, где уже есть скилсеты, не только системный, то перед установкой будет выведено предупреждение, что после установки система может работать с ошибками, либо вообще перестать работать. Это возможно ввиду того, что в рамках установки будут созданы скилсеты, созданы конфиги и произойдет отписка агентов он некоторых событий.
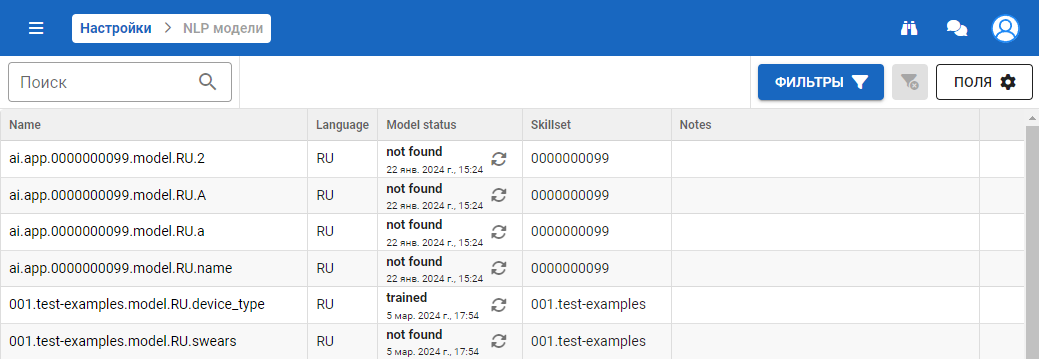
NLP модели
Данный раздел содержит информацию о всех NLP моделях стенда с возможность запустить процесс миграции. Миграция — это процесс по кодированию бинарного файла NLP модели.
Данный раздел позволяет проверить, все ли NLP модели прошли миграцию. А также перезапустить миграцию или получить информацию, почему миграция завершилась ошибкой.
Пользователи
Раздел Пользователи позволяет управлять пользователями (платформами, перечнем ролей, языком и статусами).
Раздел содержит следующие подразделы:
- Список пользователей.
- Роли.
- Статусы.
Список пользователей
Учётная запись пользователя содержит необходимую информацию о пользователе, включая id (username), отображаемое имя, язык (на котором будет вестись диалог с данным пользователем), а также присвоенные пользователю целевые системы и роли:
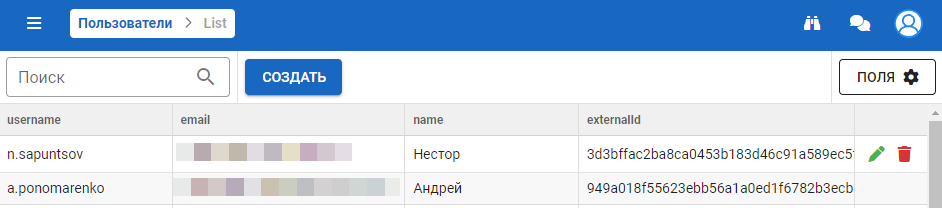
Поля:
- username — логин пользователя;
- email — почта пользователя;
- name — имя пользователя;
- language — язык пользователя в VK Assistant;
- platforms — целевые системы пользователя;
- roles — список ролей пользователя;
- Last Platform Check (скрытое поле) — когда в последний раз проверялось, есть ли такой юзер в целевой системе. Проверяется на старте сессии, если не проверялось N времени (настраиваемый параметр).
Создание пользователя
При создании пользователя указывается его email, логин (username), пароль для авторизации в VK Assistant, имя (name) и язык.
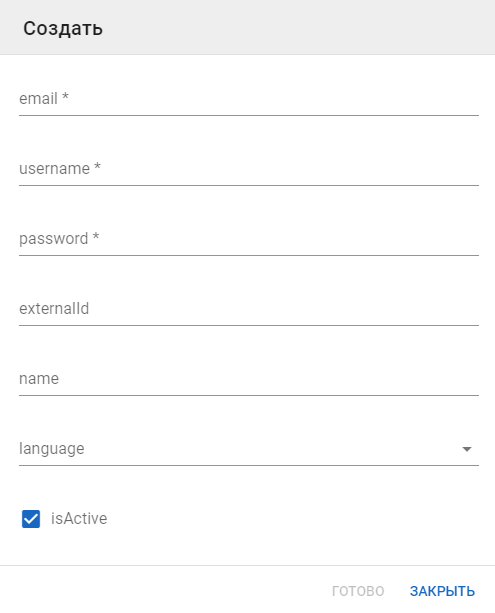
Роли пользователя
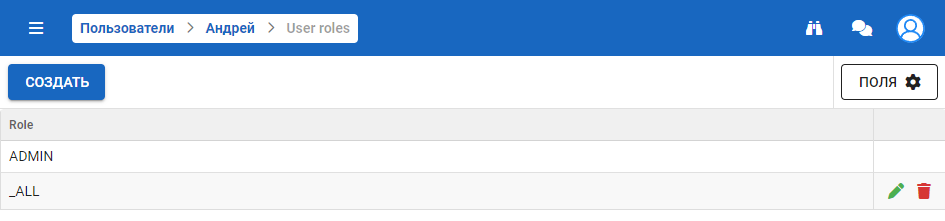
В этом разделе выполняется ведение ролей, необходимых для разграничения полномочий пользователей – как доступ к тем или иным функциям системы, так и доступность пользователю отдельных сценариев диалога:
Целевые системы пользователя
Также пользователю могут быть доступны разные целевые системы. В случае, если платформа агента не совпадает с платформой пользователя, агент не сможет отработать.

- Добавление новой платформы пользователю
-
Просмотр и редактирование текущей платформы и данных пользователя для этой платформы.
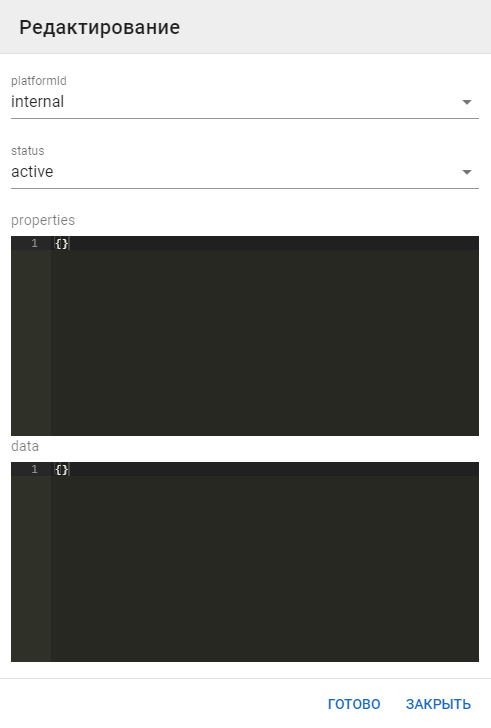
В поле data есть возможность добавлять данные о пользователе.
Роли
Блок содержит перечень всех ролей системы, которые могут быть присвоены пользователю.
Выглядит следующим образом:
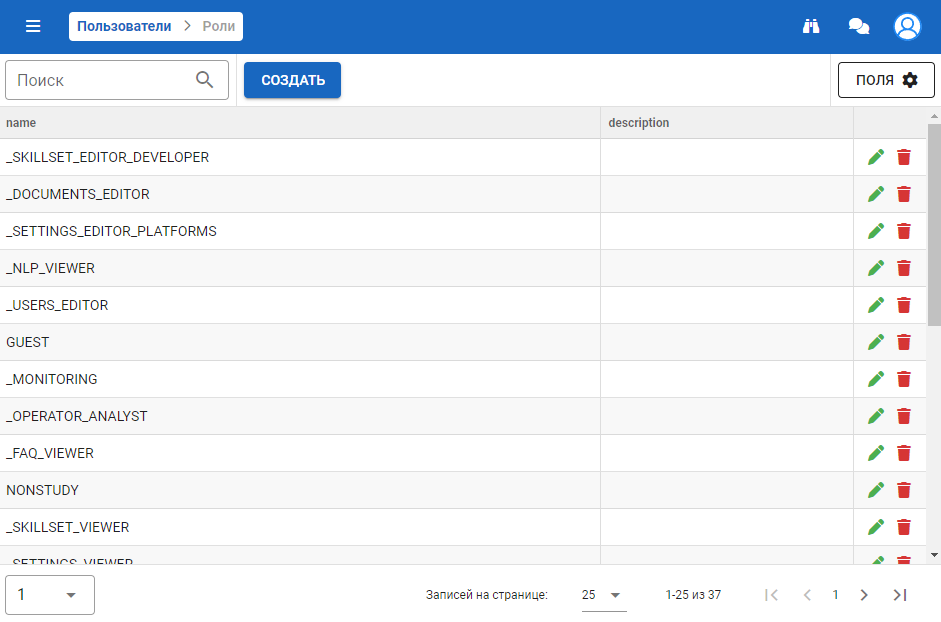
При создании роли необходимо обязательно заполнить название. Также можно заполнить описание.
Статусы
В данном блоке (доступно роли Admin) находится перечень статусов, которые могут быть назначены пользователю.
Форма выглядит следующим образом:
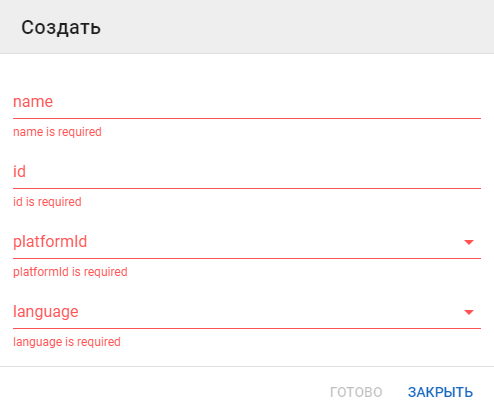
При создании роли необходимо заполнить:
- Наименование статуса
- Идентификатор статуса
- Выбрать идентификатор платформы. Возможные значения для выбора берутся из настроек системы.
- Выбрать язык. Возможные значения для выбора берутся из настроек системы.
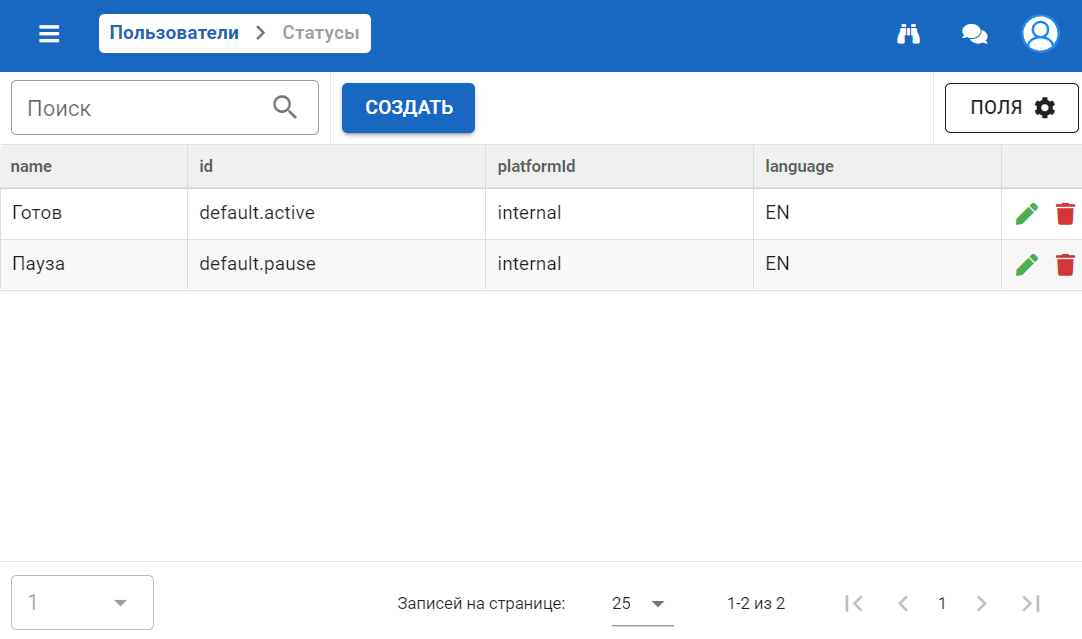
Логи
Для доступа к журналу событий необходимо к базовому url сервера добавить /adminpanel?#/logger
Для доступа через административную панель, необходимо выбрать раздел Логи/Logs в основном меню.
Раздел содержит следующие подразделы:
- Время выполнения.
- Доступ.
- Отладка.
- Задачи.
Время выполнения
Форма выглядит следующим образом:
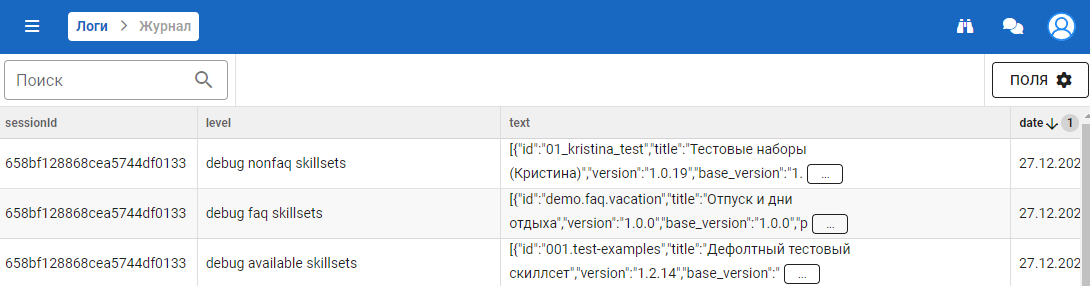
Перечень полей:
| № | Наименование | Описание |
|---|---|---|
| 1 | sessionId | Идентификатор сессии |
| 2 | level | Уровень логированной информации |
| 3 | text | Текст логирования |
| 4 | date | Дата и время создания сессии Формат: DD.MM.YYYY hh.mm |
Доступ
Каждая запись содержит информацию о событии и его свойствах.
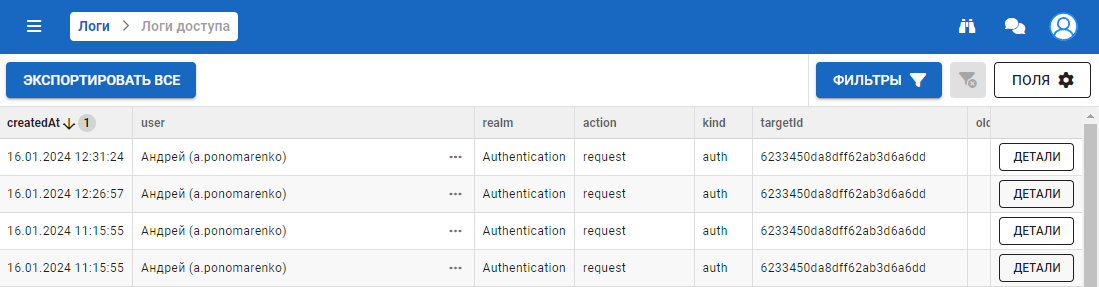
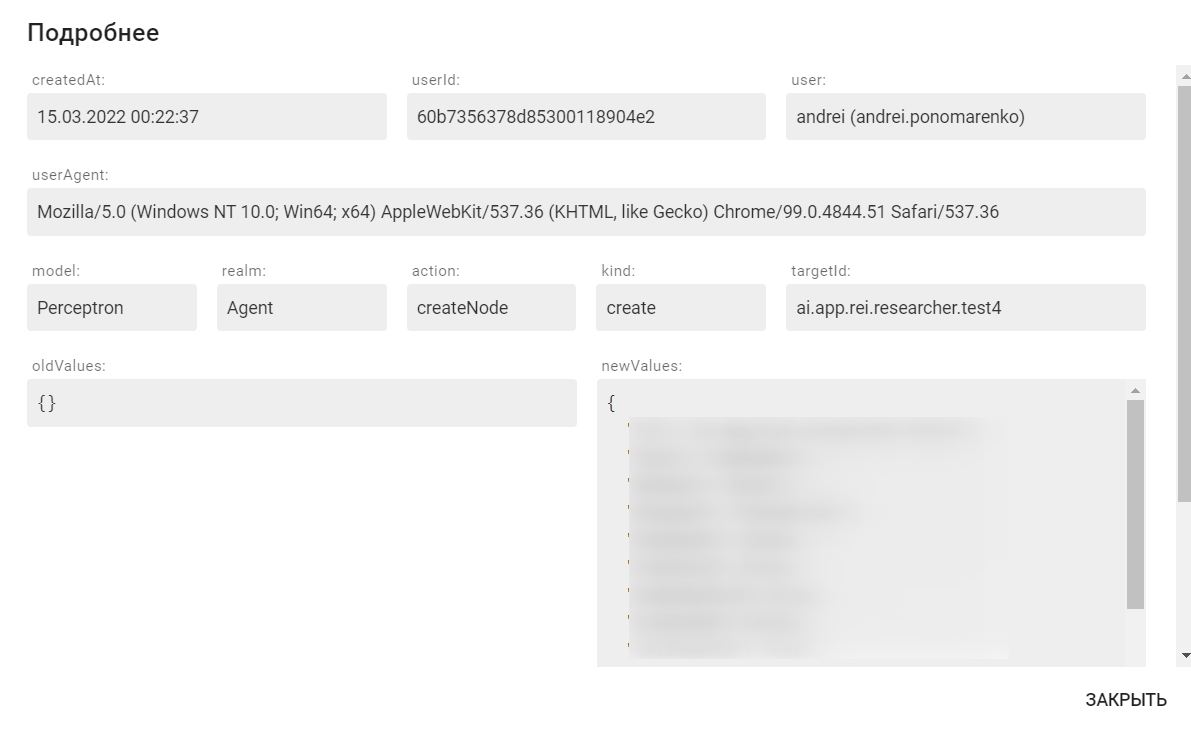
Перечень полей:
- createdAt — определяется временной промежуток для выбора событий;
- user — пользователь, совершивший действие;
- realm — модель данных, в которой произошли изменения;
- action — произошедшее действие над объектом (становится активно только после выбора модели);
- kind — общее производимое действие над объектом (становится активно только после выбора модели);
- targetId — идентификатор изменяемой сущности;
- oldValues — старое значение объекта;
- newValues — новое значение объекта.
Форма детальной информации выглядит следующим образом:
Фильтрация журнала событий
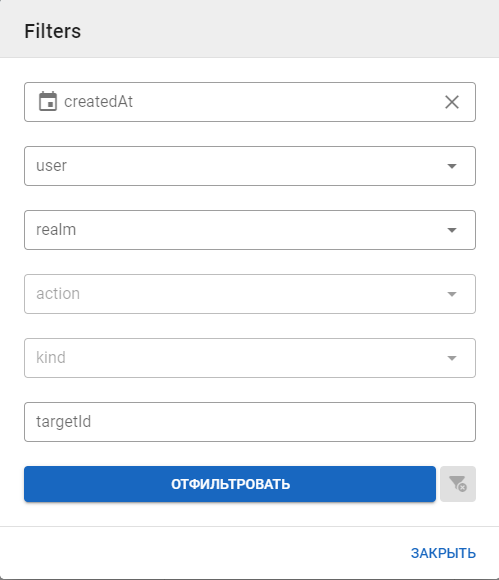
Перечень параметров для фильтрации:
- createdAt — определяется временной промежуток для выбора событий;
- user — пользователь, совершивший действие;
- realm — модель данных, в которой произошли изменения;
- action — произошедшее действие над объектом (становится активно только после выбора модели);
- kind — общее производимое действие над объектом (становится активно только после выбора модели);
- targetId — идентификатор изменяемой сущности.
Отладка
Описание подраздела представлено в документе Работа в интерфейсе оператора.
Задачи
На данной форме выводится информация о задачах.
Форма выглядит следующим образом:
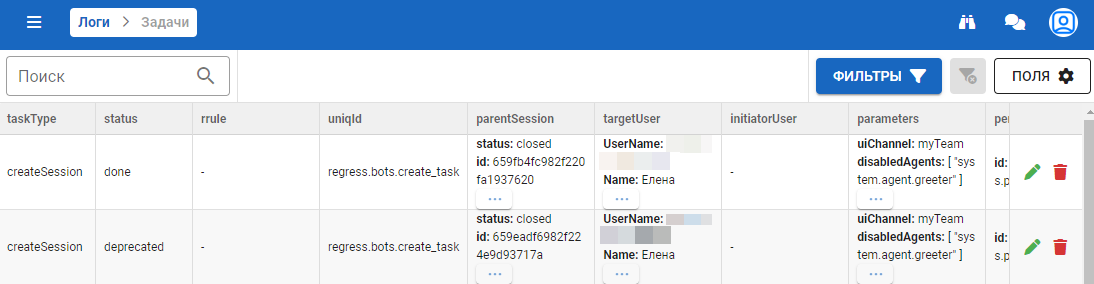
Поля:
- taskType — тип таска;
- status — статус;
- rrule — периодичность подписки;
- uniqId — уникальный идентификатор таска;
- parentSession — информация о сессии;
- targetUser — пользователь, на которого создали таск;
- initiatorUser — кто создал таск;
- parameters — параметра таска;
- perceptronId — идентификатор персептрона;
- createdAt — дата создания;
- startTime — дата начала;
- lastStartedAt — дата последнего старта таска;
- updatedAt — дата обновления таска.
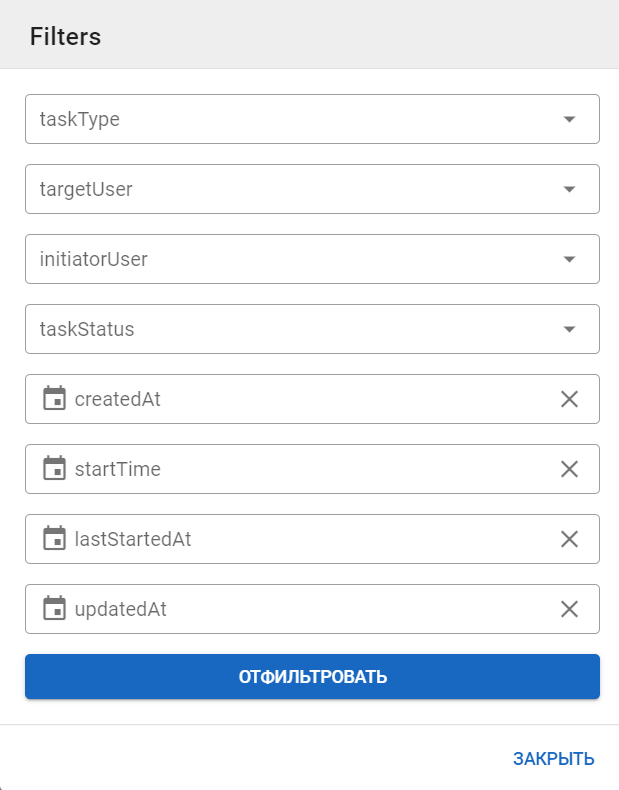
Форма фильтрации:
Статистика
Раздел состоит из двух подразделов:
- Список сессий — информация о всех сессиях с возможностью просмотра информации о сессии.
- Переобучение — на данный момент используется для статистики переходов между сценариями и сохранения нераспознанных реплик.
Список сессий
Для доступа к Списку сессий необходимо к базовому url сервера добавить /adminpanel/#/statistic/session-list
Меню списка сессий позволяет посмотреть статистику всех сессий текущего сервера. В меню доступны:
- Экспорт статистики сессий.
- Фильтрация списка сессий.
- Список сессий.
- Содержание статистики каждой сессии (доступна настройка отображения).
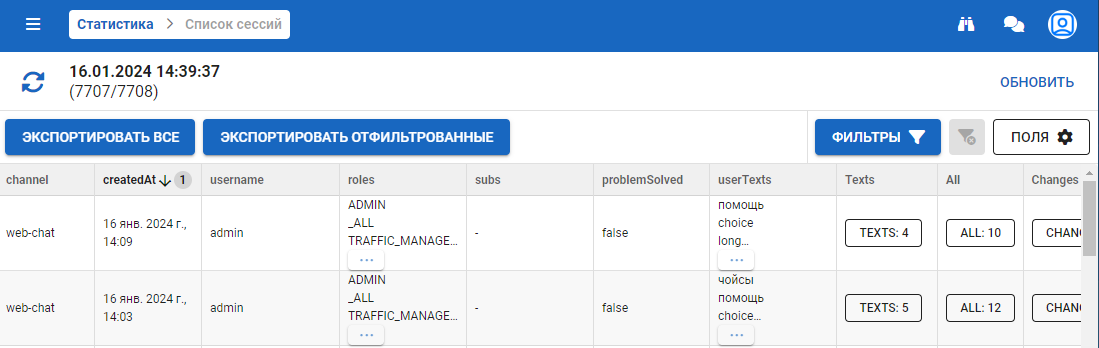
Экспорт списка сессий
Платформа обеспечивает возможность экспорта списка сессий в формате XLSX-файла. Доступно два режима экспортирования:
- кнопка Экспортировать все — экспорт списка сессий по всем сессиям;
- кнопка Экспортировать отфильтрованное — экспорт списка сессий с учетом установленных фильтров, для списка сессий.
Кастомизация выгружаемого файла:
-
Откройте Конфигурации (Основное меню -> Настройки -> Конфигурации)
-
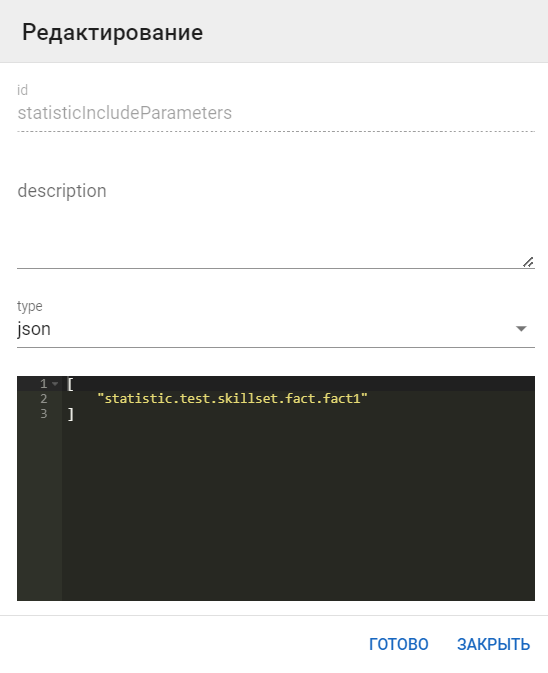
Найти конфиг statisticIncludeParameters и начать редактировать его. Выбрать в поле type значение json, а в редакторе json перечислить все факты и тайтлы тех фактов, которые хотим импортировать в файл статистики, например факт: statistic.test.skillset.fact.fact1.
-
Для настройки данных для экспорта статистики аналогичным образом создайте еще один файл:
- id конфига: statisticExportHeaders
- value:
[ { "field": "sessionId", "title": "id" }, { "field": "username", "title": "User" }, { "field": "userId", "title": "User id" }, { "field": "createdAt", "title": "Created at" }, { "field": "title", "title": "Title" }, { "field": "solved", "title": "Problem solved" }, { "field": "changes", "title": "Perceptron changed" }, { "field": "userTexts", "title": "User texts" }, { "field": "allTexts", "title": "All texts" }, { "field": "direction", "title": "Direction" }, { "field": "message", "title": "Message" }, { "field": "ai_qubo_srm_partnerIdExt", "title": "partnerIdExt" } ]
Такая настройка позволит при следующем сборе статистики собрать все нужные данные и выгрузить их в файл. Параметр будет отображен только для сессий с «последнего обновления» статистики, так как для старых сессий данный параметр не был включен в структуру.
Фильтрация списка сессий
Для удобства поиска по сессиям в меню присутствует возможность отфильтровать сессии. Для этого нажмите кнопку Фильтры (для сбора всех фильтров можно воспользоваться кнопкой  ) и настройте фильтры в открывшемся окне:
) и настройте фильтры в открывшемся окне:

Администратору доступны следующие фильтры сессий:
- Channel — фильтрация по каналу, с помощью которого пользователь взаимодействовал с системой.
- Platform — целевая система.
- Язык.
- State — статус сессии.
- Date range — период времени.
- Пользователь.
- Role — роль пользователя.
- Problem solved — решена ли задача.
- Perceptron changes — изменялся ли персептрон в рамках сессии.
- Текс пользователя — по текстам, введенным пользователями.
Параметры статистики сессии
В данной таблице описаны все параметры, которые записываются в списке сессий:
| № | Название | Тип | Описание |
|---|---|---|---|
| 1 | id | <ObjectId> | id записи в таблице SessionStatistic |
| 2 | sessionId | <ObjectId> | id сессии, по которой была собрана статистика |
| 3 | uiChannel | <String> | Канал, в котором создана сессия (возможные варианты: ["web-chat", "built-in-chat", "s4b", "telegram", ...]; по умолчанию "web-chat") |
| 4 | platformId | <ObjectId> | Целевая система сессии, по умолчанию "internal" |
| 5 | language | <String> | Язык общения с пользователем, по умолчанию "EN" |
| 6 | perceptronId | <ObjectId> | id персептрона, в котором сессия находилась на момент сбора статистики |
| 7 | debugLevel | <number> | Число, обозначающее уровень логирования процессов и событий, происходящих в сессии; по умолчанию 0 (отключен) |
| 8 | ttl | <number> | Время в секундах, прошедшее от последнего события в сессии, по истечению которого ее статус будет автоматически изменен на "closed" |
| 9 | state | <String> | Статус сессии на момент сбора статистики, по умолчанию "opened" |
| 10 | stateChangedAt | <Date> | Дата последнего изменения статуса сессии, формат "DD.MM.YY hh:mm:ss" |
| 11 | createdAt | <Date> | Дата создания сессии, формат "DD.MM.YY hh:mm:ss" |
| 12 | updatedAt | <Date> | Дата последнего изменения записи в таблице Session, формат "DD.MM.YY hh:mm:ss" |
| 13 | title | <String> | Заголовок, установленный вручную, или же равняется первому сообщению пользователя в данной сессии |
| 14 | isOperator | <Boolean> | Признак того, что сессия является операторской, по умолчанию false |
| 15 | operatorId | <ObjectId> | id пользователя с ролью оператор, назначенного на эту сессию, по умолчанию null |
| 16 | userId | <ObjectId> | id пользователя, от лица которого была создана сессия |
| 17 | username | <String> | Логин пользователя, от лица которого было создана сессия |
| 18 | name | <String> | Имя пользователя, от лица которого было создана сессия; может быть пустым, так как это не обязательное поле для пользователя |
| 19 | roles | <Array[String]> | Массив ролей пользователя, от лица которого было создана сессия |
| 20 | userTexts | <Array[String]> | Массив сообщений от пользователя |
| 21 | allTexts | <Array[Object]> | Массив из объектов, представляющих все сообщения и их метаданные, переданные в рамках сессии |
| 22 | changes | <Boolean> | Флаг, сигнализирующий об изменении персептрона в рамках сессии |
| 23 | perceptronChanges | <Array[Object]> | Массив из событий смены персептрона в рамках сессии |
| 24 | solved | <Boolean> | Ответ пользователя на шаблонный запрос при окончании сессии "Решена ли ваша проблема?" |
| 25 | id SessionParameter | <SessionParameter> | SessionParameter.value's, собираемые в статистику при передаче их id в Config ["statisticIncludeParameters"] |
Просмотр содержания сессии
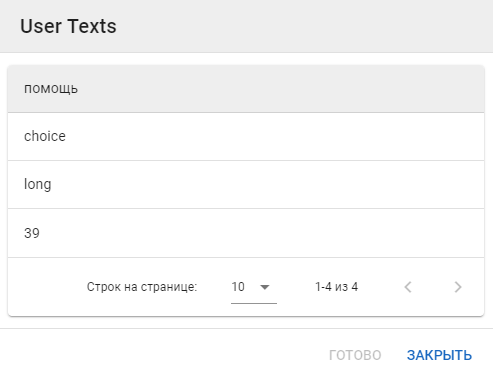
Чтобы посмотреть содержание сессии, выберите поля Texts, All или Changes.
-
Кнопка Texts позволяет просмотреть все реплики пользователя:
-
Кнопка All позволяет просмотреть все тексты диалога:
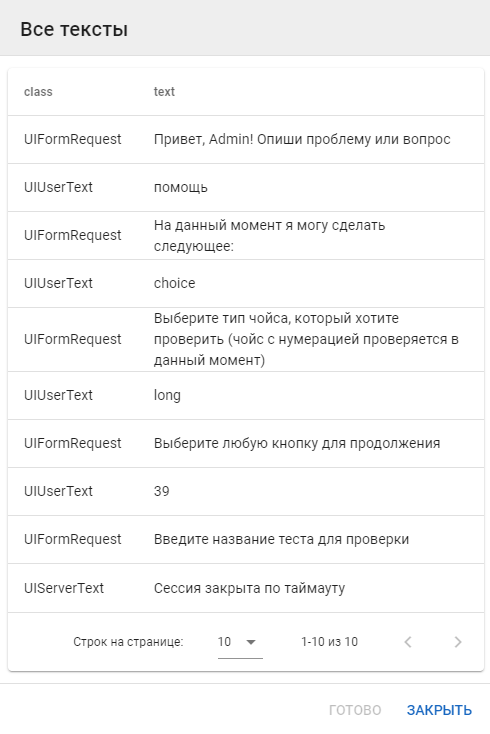
-
Кнопка Changes позволяет посмотреть техническую информацию о смене скилсета в рамках сессии:
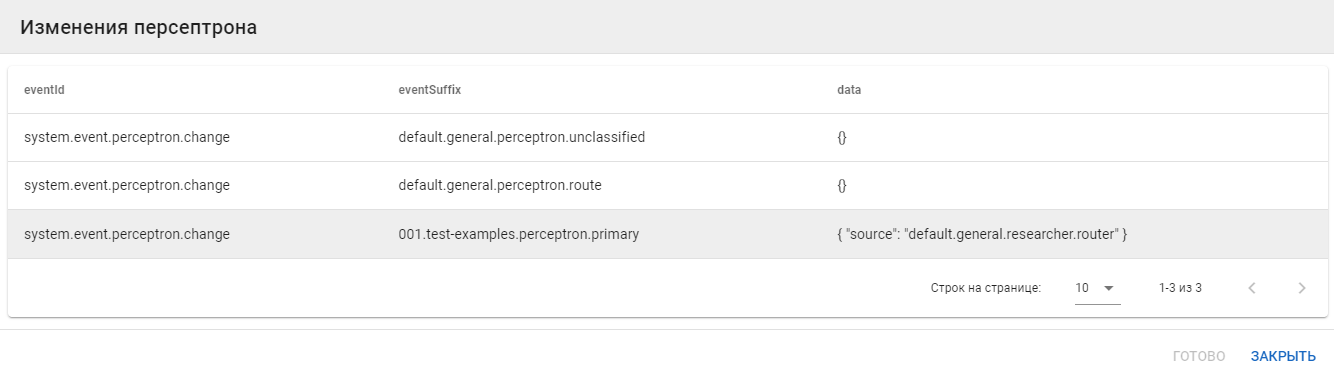
Переобучение (Retraining)
Позволяет в процессе общения с пользователем сохранять «непонятые» или «неверно распознанные» данные в Retraining для дальнейшего анализа текстов.
На основной форме находится информация о перечнях блоков для анализа:
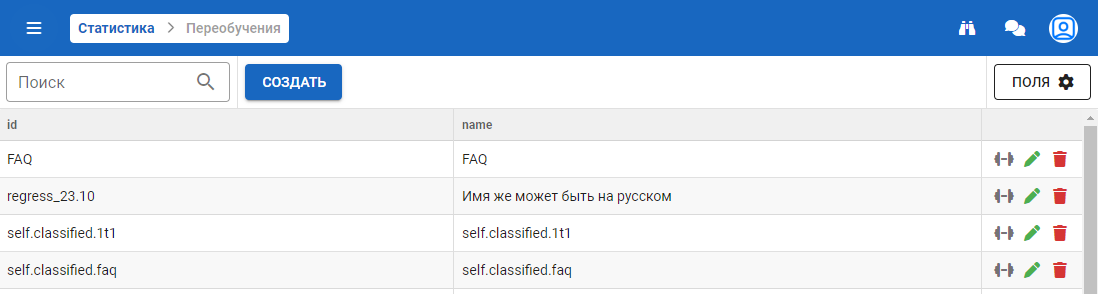
Каждый блок содержит в себе список, где строка состоит из следующих параметров:
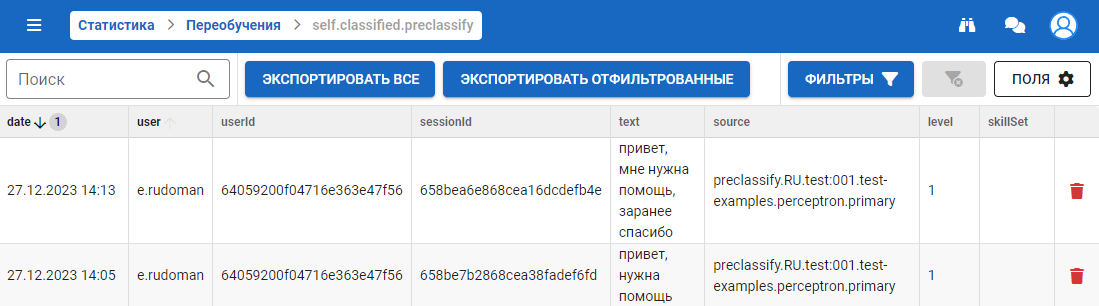
, где:
- date — дата создания записи приведенная к локальному времени;
- user — логин пользователя;
- userId — идентификатор пользователя, который прислал сообщение;
- sessionId — идентификатор сессии;
- text — текст пользователя;
- source — процент классификации текста;
- level — уровень вложенности тематик, на которых не прошла классификация (1 - глобальный классификатор, 2 - локальный классификатор);
- skillSet — скилсет, в котором не удалось распознать тематику сообщения.
Для записи значений из сессии можно использовать метод: addRetrainingData.
Информация
В данном разделе находится информация о следующих данных:
- Версии системы — содержит информацию о версиях компонент стенда, описании релиза и лицензиях.
- Описание API — содержит описание методов API.
- Метрики — переадресовывает на сервис с бизнесовыми и техническими показателями.
Версии системы
Подраздел Версии системы содержит данные о всех модулях данного инстанса, их версиях и компонентах.
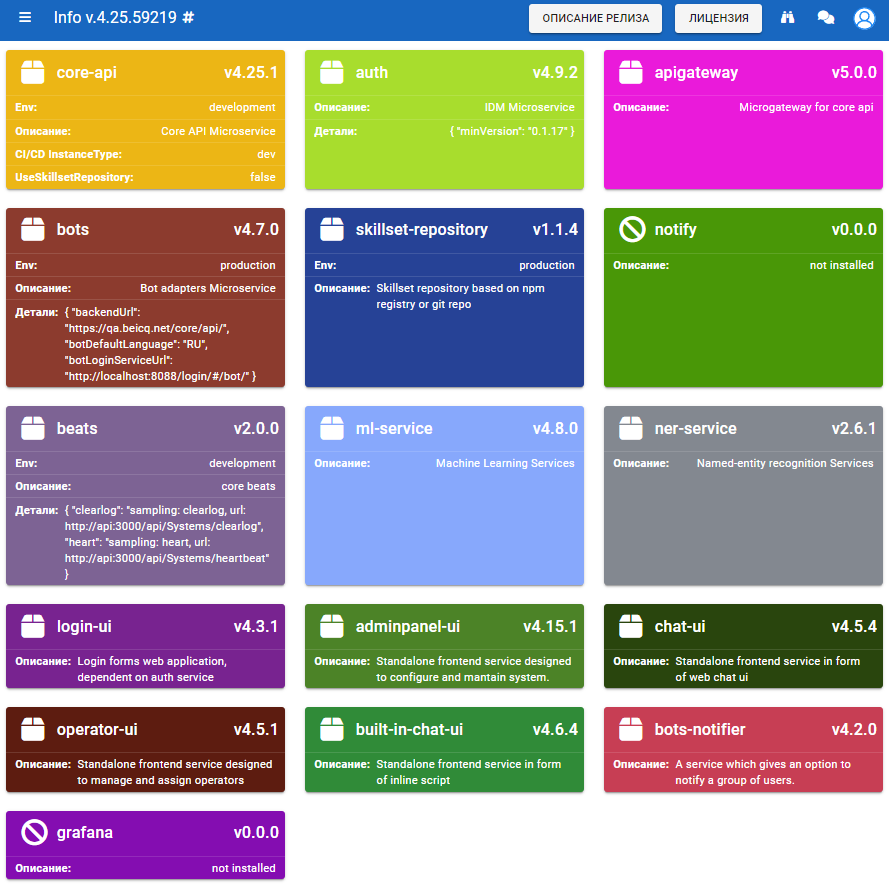
Также на данной форме находится кнопка Описание релиза, по которой открывается краткая информация изменений в релизе, номер релиза, отклонения версий компонент от релизных:
Чтобы просмотреть информацию о лицензиях, нажмите на кнопку Лицензии:
Метрики
Данный подраздел осуществляет переход (управляется при помощи конфига metrics_url) в Grafana, где есть настроенная доска с бизнесовыми и техническими показателями (на данный момент не все они показывают информацию, так как для вывода информации по некоторым показателям не хватает собираемых метрик в системе).
На доске в Grafana есть два подраздела, один для бизнесовых показателей, другой для технических показателей:
Запись метрик при помощи агентов
Бизнесовые метрики также можно записывать при помощи AgentHelper, используя метод monitor.
Бизнесовые данные для отображения в Grafana
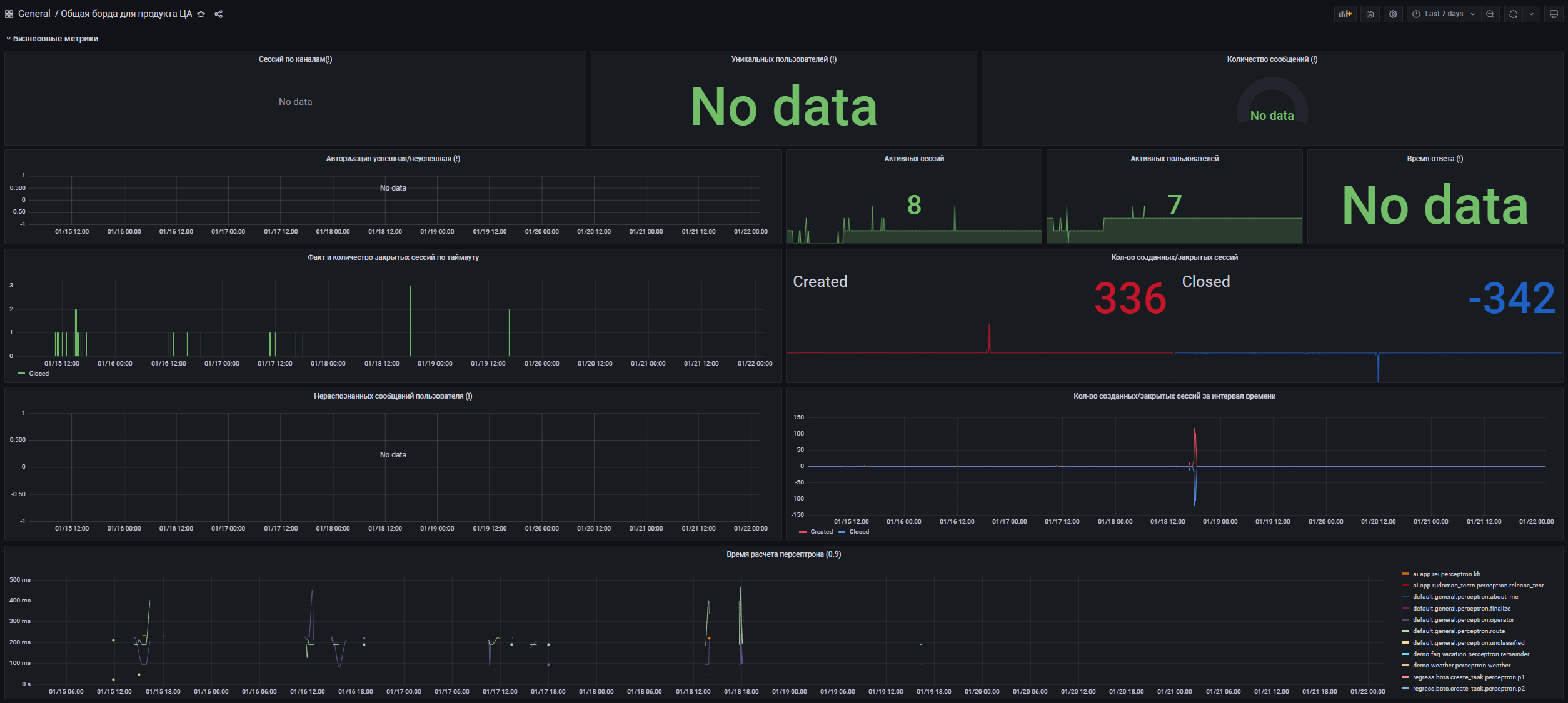
- Количество сообщений пользователей по каналам*.
- Количество уникальных пользователей, создавших сессию*.
- Количество сообщений*.
- Количество успешных/неуспешных авторизаций по каналам*.
- Количество активных сессий.
- Количество активных пользователей.
- Время ожидания ответа*.
- Количество закрытых по таймауту сессий в интервал времени.
- График факта создания/закрытия сессий в момент времени.
- Количество не успешных ответов на первом/втором уровнях классификации*.
- Количество созданных сессий по каналам*.
- Время расчета персептронов (90%).
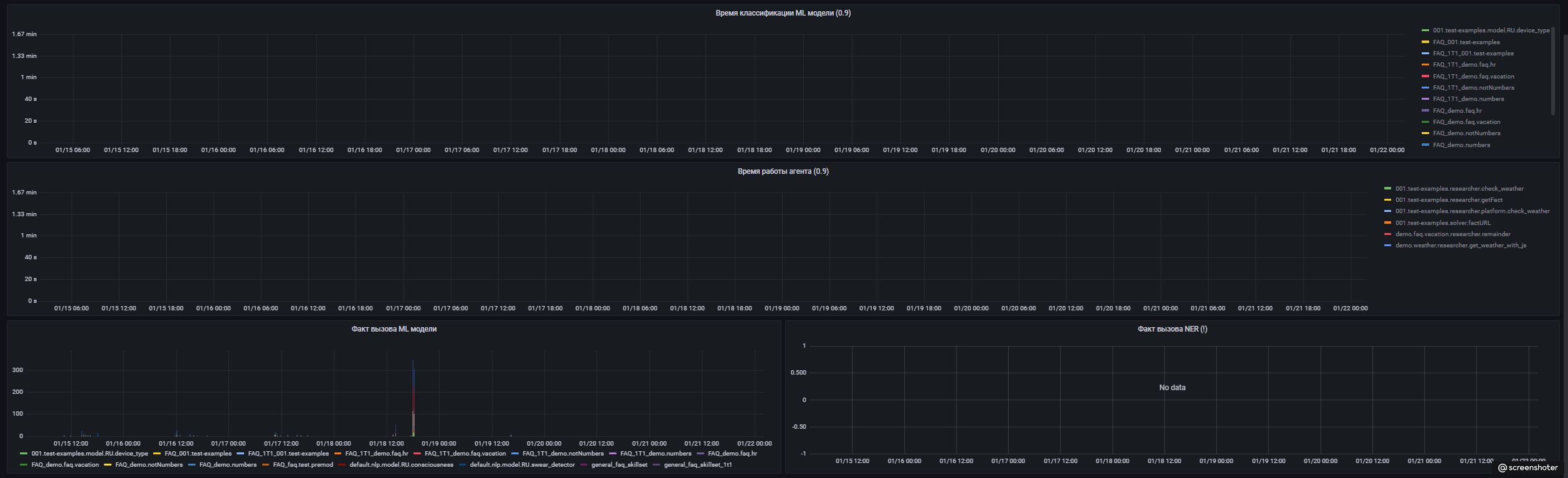
- Время классификации NLP моделей (90%).
- Время работы агентов (90%).
- График факта вызова конкретных ML-моделей (из ML).
- График факта вызова конкретных NER сервисов (из NER)*.
, где * — метрик для подсчета параметров пока нет.
Технические данные для отображения в Grafana
- Дата последней чистки логов.
- Время чистки логов.
- Время ответа сервисов (90%)*.
- Количество ошибок входящего трафика (4ХХ, 5XX)*.
- Количество ошибок внутрисетевых (4ХХ, 5XX, enotfound)*.
- Загруженность CPU*.
- Загруженность на диске (в процентах и в фактической величине)*.
- Использование памяти каждым сервисом + базы данных*.
- Загруженность очереди Redis и Celery (количество записей)*.
- Сетевой трафик (из вне) (на ingress)*.
- Сетевой трафик (межсервисный) (докерная сетка)*.
, где * — метрик для подсчета параметров пока нет.
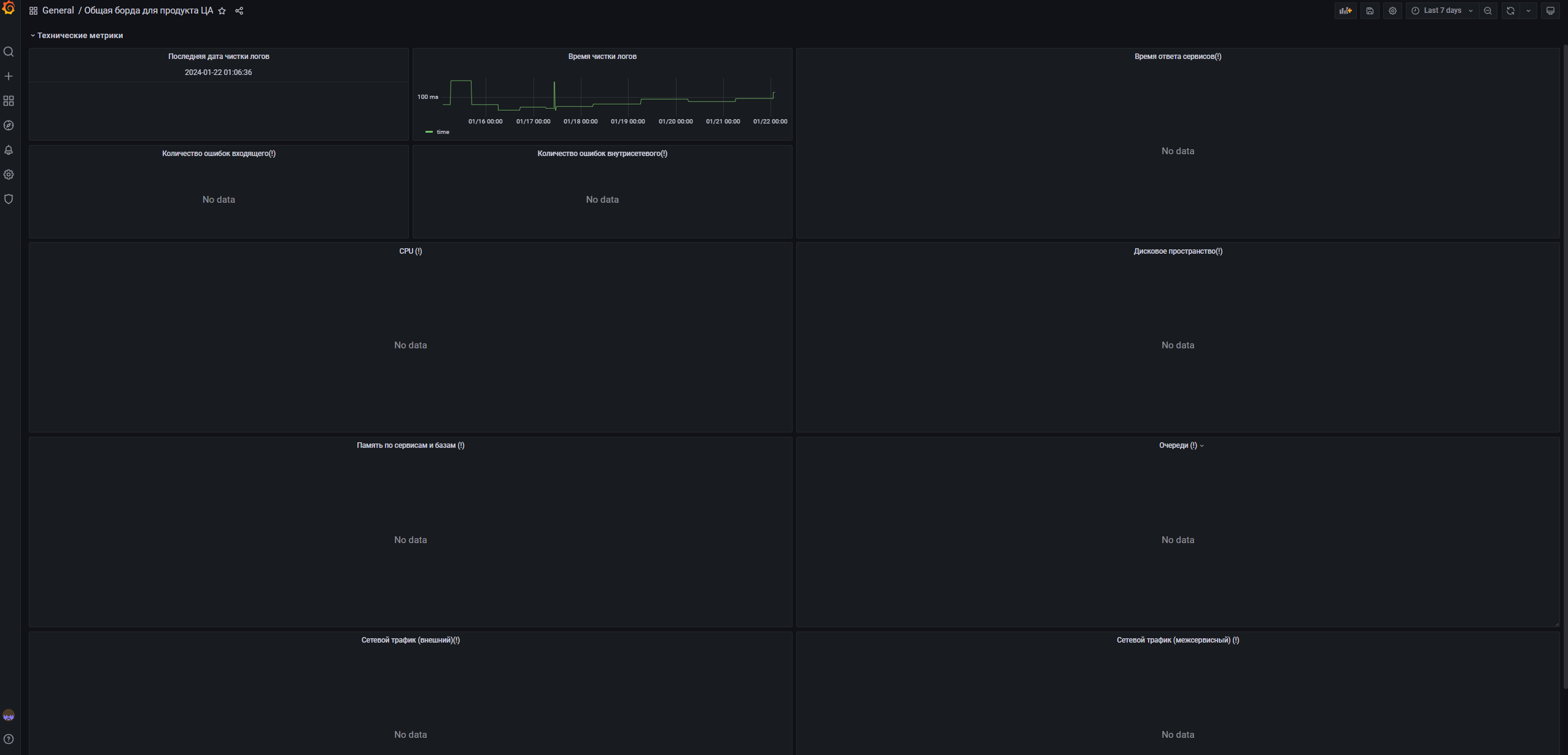
Таблица метрик разделенная по сервисам:
| ID | Тип | Назначение |
|---|---|---|
| Core API | ||
| core_api_active_sessions_count | Gauge | Количество активных сессий (сессии со статусом не closed) |
| core_api_active_users_count | Gauge | Количество активных пользователей (уникальные userId в активных сессиях) |
| core_api_dispatcher_perceptron_calc_seconds | Histogram | Гистограмма длительности расчета перцептрона |
| core_api_messages_total | Counter | Количество входящих и исходящих сообщения по каналам |
| core_api_ml_classify_seconds | Histogram | Гистограмма длительности ML классификации |
| core_api_agent_run_seconds | Histogram | Гистограмма длительности Remote агента |
| core_api_session_sub_seconds | Histogram | Гистограмма длительности под-сессии |
| core_api_sessions_created | Counter | Счетчик создания сессий |
| core_api_sessions_closed | Counter | Счетчик закрытия сессий |
| core_api_sessions_timeouted | Counter | Счетчик сессий закрытых по таймауту |
| core_api_agent_error | Counter | Счетчик количества ошибок в агентах |
| core_api_unsuccessful_access_to_sap | Counter | Счетчик количества ошибок в запуске SAP агентов |
| core_api_unsuccessful_access_to_agent | Counter | Счетчик ошибок при запуске агента, который использует данные пользователя. |
| core_api_unseccessful_mail | Counter | Счетчик ошибок при отправке почты через агент хелпера. |
| core_api_last_clear_logs_duration_seconds | Gauge | Длительность последней чистки логов |
| core_api_last_clear_logs_date | Gauge | Дата последней чистки логов |
| core_api_clear_logs_error | Counter | Счетчик ошибок при чистке логов |
| Core APIGateway | ||
| route_allowed | Counter | Проверка на права пройдена успешно |
| route_denied | Counter | Проверка на права пройдена НЕ успешно |
| route_404 | Counter | Ресурс не найден |
| Core Bots | ||
| core_bots_myteam_events_count | Counter | События обработанные через myTeam bots api |
| core_bots_myteam_longpoll_error_count | Counter | Ошибки запроса событий |
| core_bots_myteam_last_success_longpoll_date | Gauge | Время последнего успешного ответа longpoll |
| ML Service | ||
| flask_http_request_duration_seconds | Histogram | Время между запросом и ответом. |
| flask_http_request_total | Counter | Общее количество HTTP запросов. |
| flask_http_request_exceptions_total | Counter | Общее число ошибок при HTTP запросах. |
| NER Service | ||
| http_requests_total | Counter | Общее количество запросов. |
| http_request_size_bytes | Summary | Суммарная длина контента всех входящих запросов. |
| http_response_size_bytes | Summary | Суммарная длина контента всех исходящих ответов. |
| http_request_duration_seconds | Histogram | Время между запросом и ответом. |
| http_request_duration_highr_seconds | Histogram | Максимальное время между запросом и ответом. |
Типы метрик
При мониторинге Prometheus метрики можно описать четырьмя способами:
- Счетчик (Counter)
- Измерители (Gauge)
- Гистограмма (Histogram)
- Сводки (Summaries)
Счетчик (Counter)
Это, наверное, самый простой тип метрик. Счетчик считает элементы за период времени. Если вы хотите посчитать, например, ошибки HTTP на серверах или посещения веб-сайта, используйте счетчик. Счетчик может только увеличивать или обнулять число, поэтому не подходит для значений, которые могут уменьшаться, или для отрицательных значений. С его помощью особенно удобно считать количество наступлений определенного события за период времени, т. е. показатель изменения метрики со временем.
Измерители (Gauge)
Измерители имеют дело со значениями, которые со временем могут уменьшаться. Их можно сравнить с термометрами — если посмотреть на термометр, увидим текущую температуру.
Измерители идеально подходят для измерения текущего значения метрики, которое со временем может уменьшиться. Измеритель не показывает развитие метрики за период времени. Используя измерители, можно упустить нерегулярные изменения метрики со временем. Если система отправляет метрики каждые 5 секунд, а Prometheus скрепит целевой объект каждые 15, в процессе можно потерять некоторые метрики. Если выполнять дополнительные вычисления с этими метриками, точность результатов окажется еще ниже. У счетчика каждое значение агрегировано. Когда Prometheus собирает его, он понимает, что значение было отправлено в определенный интервал.
Гистограмма (Histogram)
Более сложный тип метрики. Она предоставляет дополнительную информацию. Например, сумму измерений и их количество.
Значения собираются в области с настраиваемой верхней границей. Поэтому гистограмма может:
- Рассчитывать средние значения, то есть сумму значений, поделенную на количество значений.
- Рассчитывать относительные измерения значений, и это очень удобно, если нужно узнать, сколько значений в определенной области соответствуют заданным критериям. Особенно это полезно, если нужно отслеживать пропорции или установить индикаторы качества.
Сводки (Summaries)
Расширенные гистограммы. Они тоже показывают сумму и количество измерений, а еще квантили за скользящий период. Квантили — это деление плотности вероятности на отрезки равной вероятности.
Итак: гистограммы или сводки?
Все зависит от намерения. Гистограммы объединяют значения за период времени, предоставляя сумму и количество, по которым можно отследить развитие определенной метрики. Сводки, с другой стороны, показывают квантили за скользящий период (т. е. непрерывное развитие во времени). Это особенно удобно, если вам нужно узнать значение, которое представляет 95% значений, записанных за период.
Описание API
В данном подразделе находится информация о всех методах API.
Дополнительно
Встраивание в административную панель сторонних веб-приложений в том же домене по путям.
Для отображения страницы кастомный компонент должен находиться по тому же адресу, что и админ панель (должен быть один и тот же порт и хост), тогда будет передаваться аутентификация админа, и страница будет доступна. Настройки производятся при помощи конфига moreMenuItems.
Например, на данной форме размещены следующие страницы:
- BuiltIn — встроенный в административную панель чат;
- Chat — стандартный чат;
- Operator — операторский интерфейс;
- Admin Panel — встроенная административная панель цифрового ассистента.
