Ошибки
Ошибка запуска сервисов tarantool после аварийного завершения работы сервера
При аварийном завершении работы односерверной инсталляции, модуль xlog в Tarantool может быть повреждён. При поврежденном xlog Tarantool не будет запускаться, а в логах сервиса будут ошибки вида failed to initialize storage:
окт 24 15:26:21 demo-02-mail01 onpremise-container-xtaz2[193871]: 2024-10-24 15:26:21.436 [1] main/103/xtaz F> can't initialize storage: invalid magic: 0x0
или
апр 23 16:04:14 demo-02-mail01 onpremise-container-wopi-tar2[3223028]: 2024-04-23 16:04:14.554 [22] main/103/init.lua F> can't initialize storage: /var/lib/tarantool/xlogs//00000000000000000068.xlog: signature check failed
Чтобы устранить проблему:
- В веб-интерфейсе установщика, перейдите в раздел Настройки -> Переменные окружения.
- В левом боковом меню найдите сервис, который выдает ошибку.
- Нажмите кнопку редактировать
 .
. - Нажмите на кнопку + Добавить.
- В поле Название переменной введите
TARANTOOL_FORCE_RECOVERY, в поле Значение переменной введите значениеtrue. - Нажмите на кнопку + Добавить.
- В поле Название переменной введите
FORCE_RECOVERY, в поле Значение переменной введите значениеtrue. -
Нажмите Сохранить.

-
Выполните шаг up_container для сервиса.
- После успешного запуска сервиса удалите переменные окружения
TARANTOOL_FORCE_RECOVERYиFORCE_RECOVERY.
Ошибка слишком длинных имен сервера в nginx
Если используется слишком много имен серверов или эти имена слишком длинные то может возникать следующая ошибка:
could not build server_names_hash, you should increase server_names_hash_bucket_size: 64
Решение:
Увеличить значение параметра server_names_hash_bucket_size до 128 или 256 в настройках целевого nginx-a. По-умолчанию размер бакета равен 64.
Ошибка AIO для MySQL
Для ОС Astra Linux периодически возникает проблема с AIO для баз данных MySQL.
Решение:
for i in ls -1 /opt/mailOnPremise/dockerVolumes/**/mysql-conf.d/*cnf;
do echo "" >> $i; echo "innodb_use_native_aio = 0" >> $i; done
Базы данных перезапустятся сами.
В профилактических целях добавьте переменную innodb_use_native_aio = 0 в следующие контейнеры: bizdb, gravedb, mirage, seconddb, swadb, umi.
Ошибка Failed to create shim task
Может возникнуть в любом контейнере.
Ошибка:
Error response from daemon: failed to create shim task:
OCI runtime create failed: runc create failed: unable to start container process: error during container init: error running hook #0:
error running hook: exit status 1, stdout: , stderr: time="2023-05-24T13:24:04+03:00" level=fatal msg="failed to add interface temp8266b45f552 to sandbox:
error setting interface \"temp8266b45f552\" routes to [\"169.254.1.1/32\" \"fe80::7c5f:4cff:fe0c:99b6/128\"]: permission denied": unknown
Решение:
-
Проверить, что отключен ipv6:
-
Отключить ipv6 и перезапустить контейнеры, в которых возникла ошибка.
Ошибка при переполнении etcdserver: mvcc: database space exceeded
Может возникнуть во всех контейнерах связанных с etcd.
Диагностика:
docker exec -it -e ETCDCTL_API=3 infraetcd1 etcdctl endpoint status --write-out=table
docker exec -it -e ETCDCTL_API=3 infraetcd1 etcdctl alarm list
Ответ:
+----------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------------------------------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+----------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------------------------------+
| 127.0.0.1:2379 | 9cb9164b613d67b2 | 3.5.0 | 2.1 GB | true | false | 6 | 41175332 | 41175332 | memberID:11293082053618001842 |
| | | | | | | | | | alarm:NOSPACE |
+----------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------------------------------+
memberID:11293082053618001842 alarm:NOSPACE
Решение:
REVISION=$(docker exec -it -e ETCDCTL_API=3 infraetcd1 etcdctl endpoint status --write-out="json" | egrep -o '"revision":[0-9]*' | egrep -o '[0-9].*')
docker exec -it -e ETCDCTL_API=3 -e REVISION=$REVISION infraetcd1 etcdctl compact ${REVISION}
docker exec -it -e ETCDCTL_API=3 infraetcd1 etcdctl --command-timeout=5m defrag
docker exec -it -e ETCDCTL_API=3 infraetcd1 etcdctl alarm disarm
Ошибка keycloak: User with username 'mridme' already added
Решение:
-
Остановить keycloak:
-
Удалить файл
keycloak-add-user.json: -
Запустить keycloak:
Ошибка связи fedman с другой установкой Почты
Внимание
Шаги ниже применимы только при использовании продукта Интеграция с другими инсталляциями VK WorkMail, для двух и более систем. Не выполняйте шаги ниже, если fedman установлен для других интеграционных целей. Удаление tnt-fedman на единственной инсталляции приведет к некорректной работе системы.
Решение:
-
Перейти в контейнер fedman:
-
Убедиться, что внутри контейнера не видно двух fedman'ов — есть только локальный fedman:
-
Остановить контейнер tnt-fedman и удалить его с содержимым:
-
В интерфейсе установщика запустить шаг up_container для контейнера tnt-fedman.
-
Остановить контейнер fedman и удалить его вместе с содержимым:
-
В интерфейсе установщика запустить шаг up_container для контейнера fedman.
-
Если пользователь добавлен в почту, но письма не отправляются, даже самому себе — проверить, есть ли он в базе данных tnt-fedman:
-
Если пользователя нет, то скорее всего нарушена репликация fedman. Нужно остановить fedman и удалить его вместе с содержимым:
-
В интерфейсе установщика запустить шаг up_container для контейнера fedman.
Ошибка nylon при кластерной установке
Ошибка:
Call to 'get_upload_pair' with '{"pair_type":"CLOUD","request_size":10903532,"req_id":"8xw2Thieg6","source":"cld-uploader1.qdit"}' failed with 'PairDB failed processing request: '{"status":"error","error_code":3,"error_desc":"Pair not found"}''
Диагностика:
Проверить s3pairdb:
Посмотреть есть ли следующие логи:
---
- 0
- #1 status:HOTBOX st1:172.20.2.207:80/1 st2:172.20.12.207:80/1 free:49820401664/49820381184 err:1970-01-01:00:00:00/1970-01-01:00:00:00 class:CLOUD karma:2 maintenance:1970-01-01:00:00:00
#2 status:HOTBOX st1:172.20.2.207:80/2 st2:172.20.1.207:80/2 free:49820401664/49820401664 err:1970-01-01:00:00:00/1970-01-01:00:00:00 class:CLOUD karma:2 maintenance:1970-01-01:00:00:00
#3 status:HOTBOX st1:172.20.1.207:80/3 st2:172.20.12.207:80/3 free:49820401664/49820381184 err:1970-01-01:00:00:00/1970-01-01:00:00:00 class:CLOUD karma:2 maintenance:1970-01-01:00:00:00
Решение:
Пометить каждую строку с помощью следующих команд:
lua pairdb.shell.run("mark", "1", "HOTBOX,REDUNDANT")
lua pairdb.shell.run("mark", "2", "HOTBOX,REDUNDANT")
lua pairdb.shell.run("mark", "3", "HOTBOX,REDUNDANT")
Ошибка CE_BADBLOB при создании файла в облаке
- В интерфейсе установщика перейти на вкладку AdminPanel.
- Найти в списке контейнеров cld-docs и нажать на значок шестеренки справа от названия контейнера.
- Выполнить шаг upload_file_templates.
См. также: Не создается документ в VK WorkDisk, и в меню «Создать» не хватает кнопок
Ошибка configure_replication_cluster
Симптомы
В логах установщика много ошибок вида:
окт 16 15:57:17 devqa-02 deployer[525686]: 2023/10/16 15:57:17 [rpopdb1][configure_replication_cluster] failed dump from master: error execute template to dump db from master: Process exited with status 2
окт 16 15:57:17 devqa-02 deployer[525686]: 2023/10/16 15:57:17 [gravedb1][configure_replication_cluster] failed dump from master: error execute template to dump db from master: Process exited with status 2
окт 16 15:57:17 devqa-02 deployer[525686]: 2023/10/16 15:57:17 [swadb1][configure_replication_cluster] failed dump from master: error execute template to dump db from master: Process exited with status 2
Есть проблема со следующими контейнерами:
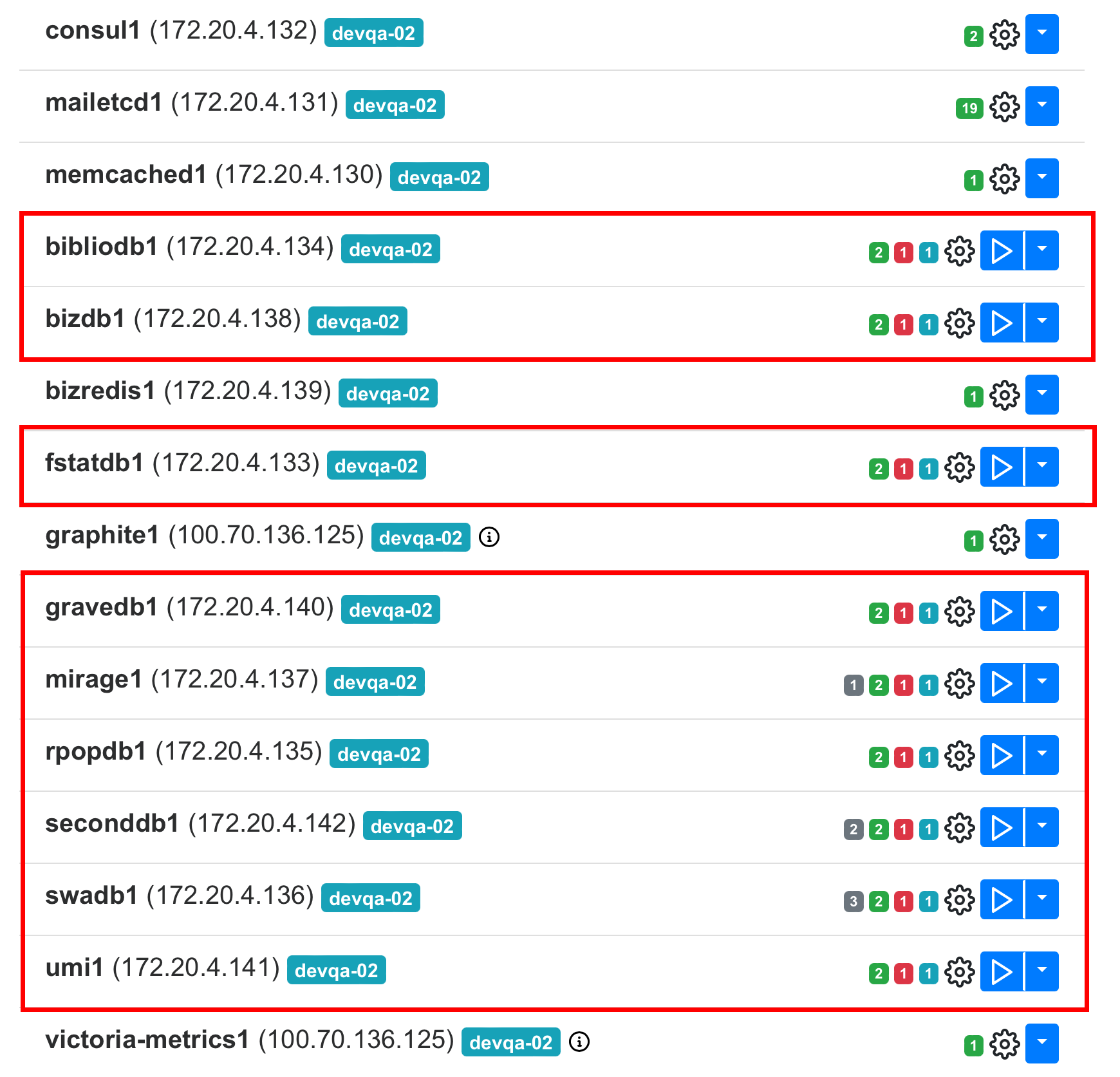
Решение:
- В интерфейсе установщика перейти на вкладку AdminPanel.
- Найти в списке контейнеров все контейнеры вида bind*.
- Для каждого контейнера нажать на значок шестеренки справа от названия контейнера и выполнить шаг up_container.
- Найти в списке контейнеров все контейнеры вида consul*.
-
Внутри каждого контейнера выполнить следующие команды:
consul kv delete orchestrator/mysql/master/bibliodb/hostname consul kv delete orchestrator/mysql/master/bizdb/hostname consul kv delete orchestrator/mysql/master/fstatdb/hostname consul kv delete orchestrator/mysql/master/gravedb/hostname consul kv delete orchestrator/mysql/master/mirage/hostname consul kv delete orchestrator/mysql/master/rpopdb/hostname consul kv delete orchestrator/mysql/master/seconddb/hostname consul kv delete orchestrator/mysql/master/swadb/hostname consul kv delete orchestrator/mysql/master/umi/hostname
Ошибка cluster not found at /mailonpremise/overlord/
Симптомы
- Не запускается контейнер calendar-notifytar.
-
В логах ошибка:
окт 17 21:46:29 devqa-01 onpremise-container-crow-usershards1[322669]: 2023-10-17T21:46:29.326+0300 ERROR get initial configuration failed {"error": "cluster not found at /mailonpremise/overlord/instances/crow-usershards1/, kv len 0: cluster not found"} окт 17 21:46:29 devqa-01 onpremise-container-crow-usershards1[322669]: 2023-10-17T21:46:29.326+0300 ERROR If cluster not found in ETCD, please check that ETCD is ready to accept connections and you make initial setup of overlord clusters. окт 17 21:46:29 devqa-01 systemd[1]: onpremise-container-crow-usershards1.service: Main process exited, code=exited, status=2/INVALIDARGUMENT окт 17 21:46:31 devqa-01 systemd[1]: onpremise-container-crow-usershards1.service: Failed with result 'exit-code'. -
В интерфейсе установщика на вкладке Настройки → Шардирование и репликация БД при клике на Опросить все Overlord'ы выдает ошибку:
Решение:
- В интерфейсе установщика перейти на вкладку AdminPanel.
- Найти в списке контейнеров все контейнеры вида mailetcd*.
- Для каждого контейнера нажать на значок шестеренки справа от названия контейнера и последовательно выполнить два шага:
- overlord_clusters;
- up_container.
- Найти в списке контейнеров calendar-notifytar.
- Нажать на значок шестеренки справа от названия контейнера и выполнить шаг up_container.
Ошибка can't run gctune
- В интерфейсе установщика перейти на вкладку Настройки → Переменные окружения.
- Найти нужный контейнер и установить переменную
{name}_GCTUNE_DISABLE=false. Например, для cexsy нужно установить переменнуюCEXSY_GCTUNE_DISABLE=false.
Полный перечень переменных:
- SWA_FAU_MAILTO_GCTUNE_DISABLE
- OVERLORD_GCTUNE_DISABLE
- BMW_GCTUNE_DISABLE
- FEDMAN_GCTUNE_DISABLE
- MAILBOT_GCTUNE_DISABLE
- OPER_GCTUNE_DISABLE
- CLOUDBIZ_GCTUNE_DISABLE
- MAILER_GCTUNE_DISABLE
- ONPREMAPI_GCTUNE_DISABLE
- POLITICS_GCTUNE_DISABLE
- CEXSY_GCTUNE_DISABLE
Внимание
Перед установкой переменной окружения рекомендуется проконсультироваться с поддержкой.
Ошибка 500 при открытии веб-интерфейса Почты
Симптомы
- Веб-интерфес деплоера открывается
- Панель администратора открывается
- Почтовые ящики не открываются с ошибкой 500
Что исследовать?
Посмотреть состояние и логи контейнеров mpop и mailapi.
Последовательность действий
-
Запустить просмотр логов контейнера
-
Перезагрузить страницу почты в браузере.
- Проверить, какая информация запишется в логи.
Ошибка 500 при входе в Почту, и в логах сервиса swa есть ошибка типа Connection refused
Симптомы
В логах сервиса swa отображается информация, аналогичная приведенной ниже:
Sep 15 21:23:34 gpuat-front-02.company onpremise-container-swa2[2445500]:
2023/09/15 18:23:34 [error] 22#0: *166 connect() failed (111: Connection refused) while connecting to upstream, client:
172.20.84.196, server: account.gpuat-mail.dev.onprem.ru, request: "GET /favicon.ico HTTP/1.0", upstream:
"http://127.0.0.1:8845/oldaccount", host: "account.gpuat-mail.dev.onprem.ru",
referrer: "https://account.gpuat-mail.dev.onprem.ru/login?page=https%3A%2F%2Fe.gpuat-mail.dev.onprem.ru%2Finbox&allow_external=1&from=octavius"
Что делать?
Удалить контейнеры swa-sota и перезапустить их:
for sota_container in $(docker container ls --filter name=swa-sota* | awk -F '[[:space:]][[:space:]]+' 'NR>1 {print $6}'); do
echo "Stopping container $sota_container"
docker container stop $sota_container
echo "Removing container $sota_container"
docker rm $sota_container
echo "Restarting service onpremise-container-$sota_container"
systemctl restart "onpremise-container-$sota_container"
done
Ошибка добавления пользователей в biz при синке с AD
Симптомы
В логах контейнера adloader фиксируется ошибка вызванная таймаутом:
Jun 05 12:40:39 gpuat-front-04.company onpremise-container-adloader4[2053374]: 2024/06/05 12:40:39 [E] [bg] [EXTERNAL_CLIENT] ATTEMPT #0: timeout from addr="127.1.3.1:10032", error Get "http://127.1.3.1:10032/api/domains/2/groups": context deadline exceeded (Client.Timeout exceeded while awaiting headers), retryingJun 05 12:40:44 gpuat-front-04.company onpremise-container-adloader4[2053374]: 2024/06/05 12:40:44 [E] [bg] [EXTERNAL_CLIENT] ATTEMPT #1: timeout from addr="127.1.3.1:10032", error Get "http://127.1.3.1:10032/api/domains/2/groups": context deadline exceeded (Client.Timeout exceeded while awaiting headers), retryingJun 05 12:40:49 gpuat-front-04.company onpremise-container-adloader4[2053374]: 2024/06/05 12:40:49 [E] [bg] [EXTERNAL_CLIENT] ATTEMPT #2: timeout from addr="127.1.3.1:10032", error Get "http://127.1.3.1:10032/api/domains/2/groups": context deadline exceeded (Client.Timeout exceeded while awaiting headers), retryingJun 05 12:40:54 gpuat-front-04.company onpremise-container-adloader4[2053374]: 2024/06/05 12:40:54 [E] [bg] [EXTERNAL_CLIENT] ATTEMPT #3: timeout from addr="127.1.3.1:10032", error Get "http://127.1.3.1:10032/api/domains/2/groups": context deadline exceeded (Client.Timeout exceeded while awaiting headers), retryingJun 05 12:40:59 gpuat-front-04.company onpremise-container-adloader4[2053374]: 2024/06/05 12:40:59 [E] [bg] [EXTERNAL_CLIENT] ATTEMPT #4: timeout from addr="127.1.3.1:10032", error Get "http://127.1.3.1:10032/api/domains/2/groups": context deadline exceeded (Client.Timeout exceeded while awaiting headers), retryingJun 05 12:40:59 gpuat-front-04.company onpremise-container-adloader4[2053374]: {"level":"warn","domain":"adm.dev.onprem.ru","error":"syncing groups: fetch from biz: fetching biz groups: error in get groups: failed to do request, given up after 5 attempts","message":"can not sync users"}
Jun 05 12:40:59 gpuat-front-04.company onpremise-container-adloader4[2053374]: {"level":"info","domain":"adm.dev.onprem.ru","message":"Finished to sync domain"}
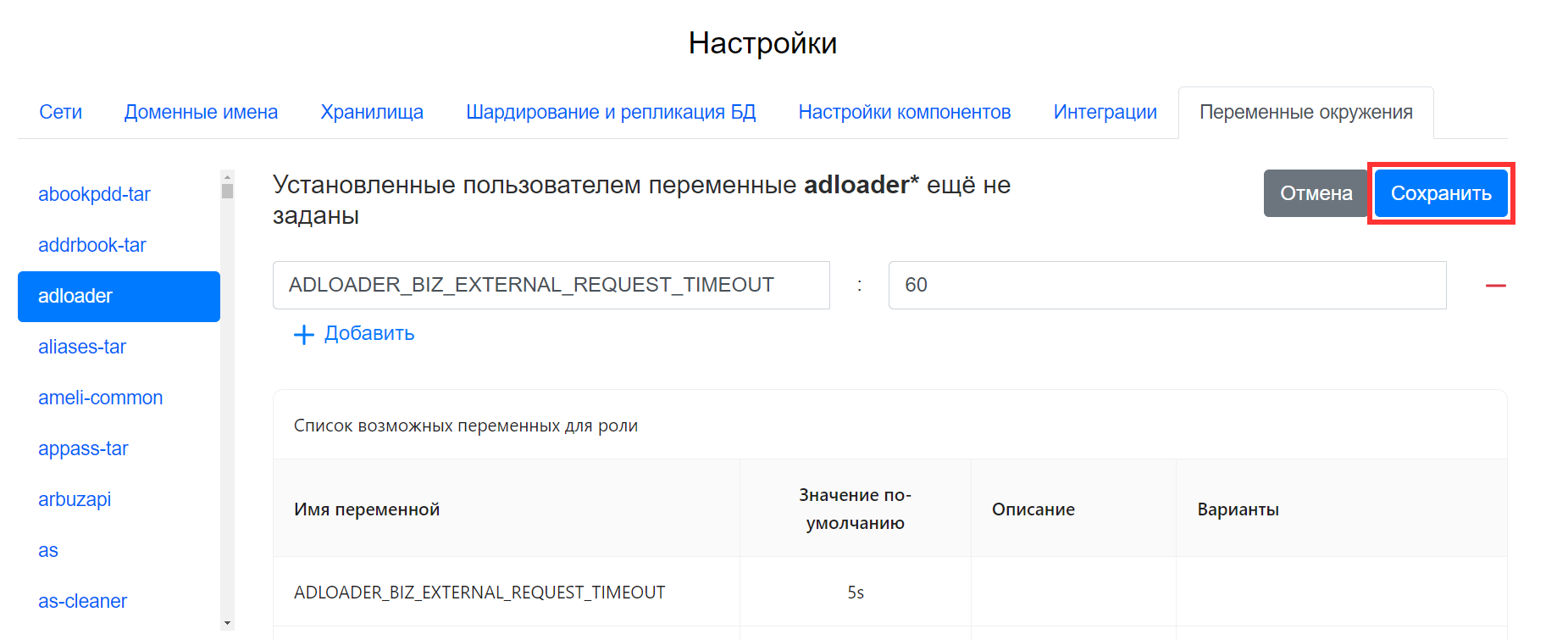
Решение
- Перейдите в веб-интерфейс установщика
http://server-ip-address:8888/. - Перейдите в раздел Настройки -> Переменные окружения.
- В списке слева найдите adloader.
- Нажмите кнопку редактировать .
- Нажмите на кнопку + Добавить.
- В поле Название переменной введите
ADLOADER_BIZ_EXTERNAL_REQUEST_TIMEOUT, в поле Значение переменной введите60s. -
Нажмите на кнопку Сохранить.
-
Перейдите на вкладку AdminPanel и найдите контейнеры adloader*.
-
Для каждого контейнера выполните шаг up_container.

Ошибка доставки письма, приходит отбивка 505 Mailbox unavailable
Симптомы
В логах контейнеров panda и del указано, что достигнут лимит в 1000000:
#panda
/var/log/workmail/spb-05-mail4/panda4.log:2024-06-07T09:49:48.107414+03:00onpremise-container-panda4[2466562]: 2024-06-07 09:49:47 96 -> 924256 1sFTQ3-003sRM-JX <= name@company.ru H=[10.80.6.37] U=root P=local S=6592 SPAMSIGN=0 REC=1 TRUST=0 id=1717742987.261686315@fmail1.qdit T="Re: 946" for name@company.ru
/var/log/workmail/spb-05-mail4/panda4.log:2024-06-07T09:49:49.148413+03:00onpremise-container-panda4[2466562]: 2024-06-07 09:49:49 1 -> 189693 1sFTQ3-003sRM-JX ** name@company.ru F=<name@company.ru> R=mpop_router T=mpop_transport: Mailbox full: name@company.ru
/var/log/workmail/spb-05-mail4/panda4.log:2024-06-07T09:49:49.148413+03:00onpremise-container-panda4[2466562]: 2024-06-07 09:49:49 1 -> 189693 1sFTQ3-003sRM-JX [DWH] bounce||1717742989||Mailbox full: name@company.ru [/DWH]
#del
/var/log/workmail/spb-05-mail4/del4.log:2024-06-07T10:01:36.718615+03:00onpremise-container-del4[2836613]: [1372256.429.172.10.125.67:55410] store [warn]: delivery res: delivery res=msg_count_limit ('messages count limit 1000000, msg count in mailbox is 1000000'), iprohdr='[msg=0,len=218,sync=1]', hsz='214', cached='1', type='rimap_local', email='name@company.ru', fsize='2778b', st_size='0b', st='127.0.0.1:|1|1|1009424|name@company.ru|1552|', needed_uidl='17176776370000024810', needed_msgflags='65540', needed_folderid='34', resp_sz='111'
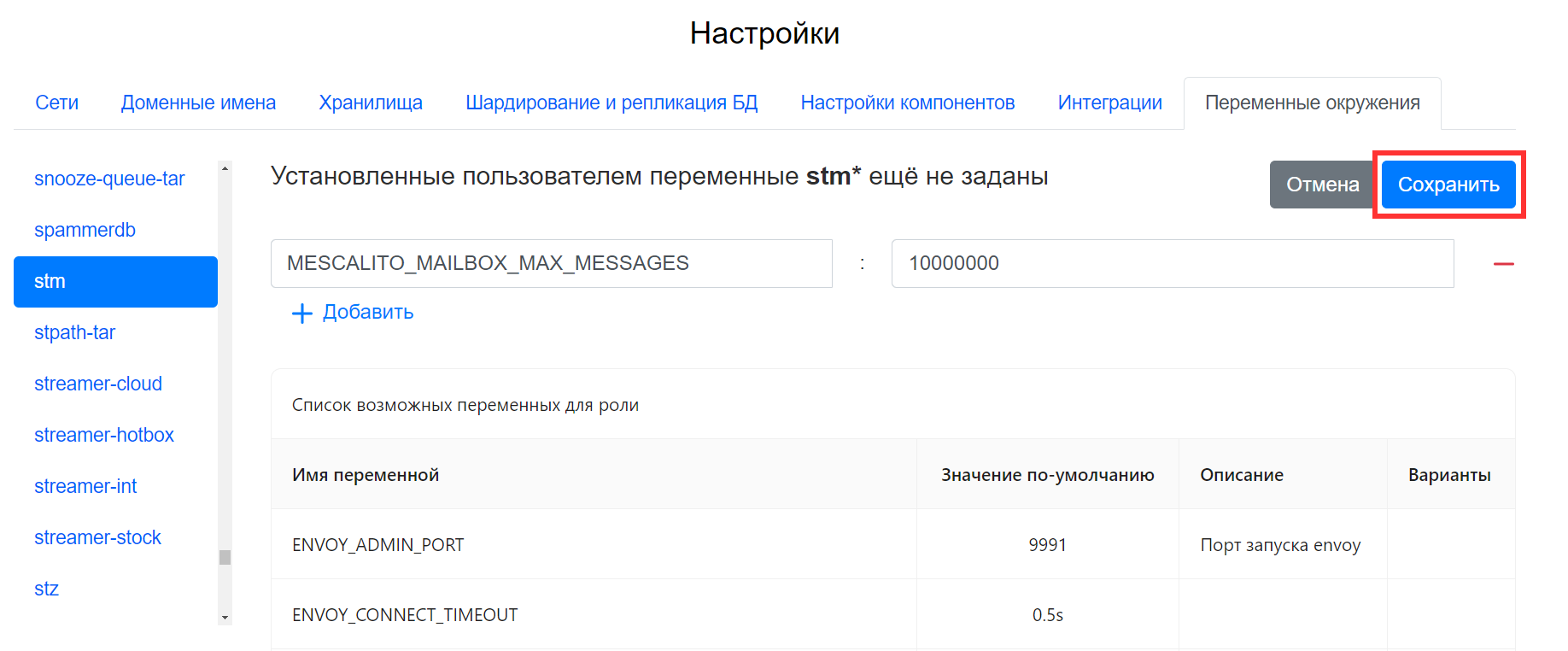
Решение
- Перейдите в веб-интерфейс установщика
http://server-ip-address:8888/. - Перейдите в раздел Настройки -> Переменные окружения.
- В списке слева найдите stm.
- Нажмите кнопку редактировать .
- Нажмите на кнопку + Добавить.
- В поле Название переменной введите
MESCALITO_MAILBOX_MAX_MESSAGES, в поле Значение переменной введите10000000. -
Нажмите на кнопку Сохранить.
-
Перейдите на вкладку AdminPanel и найдите контейнеры stm*.
-
Для каждого контейнера выполните шаг up_container.

Ошибка configure_clusters_orchestrator
Симптомы
Пользователь не инициализирован, в логах ошибки:
ноя 07 17:03:01 workmail-02 deployer[2089060]: 2023/11/07 17:03:01 [orchestrator1][configure_clusters_orchestrator] can't init databases store: can't succusfully complete initialize of clusters in orchestrator [
ноя 07 17:03:01 workmail-02 deployer[2089060]: err discovery cluster: role: umi, status:500, response: {"Code":"ERROR","Message":"Error 1045: Access denied for user 'orchesrator'@'175.20.5.104' (using password: YES)","Details":null};
ноя 07 17:03:01 workmail-02 deployer[2089060]: err discovery cluster: role: seconddb, status:500, response: {"Code":"ERROR","Message":"Error 1045: Access denied for user 'orchesrator'@'175.20.5.104' (using password: YES)","Details":null};
ноя 07 17:03:01 workmail-02 deployer[2089060]: err discovery cluster: role: gravedb, status:500, response: {"Code":"ERROR","Message":"Error 1045: Access denied for user 'orchesrator'@'175.20.5.104' (using password: YES)","Details":null};
ноя 07 17:03:01 workmail-02 deployer[2089060]: err discovery cluster: role: rpopdb, status:500, response: {"Code":"ERROR","Message":"Error 1045: Access denied for user 'orchesrator'@'175.20.5.104' (using password: YES)","Details":null};
ноя 07 17:03:01 workmail-02 deployer[2089060]: err discovery cluster: role: fstatdb, status:500, response: {"Code":"ERROR","Message":"Error 1045: Access denied for user 'orchesrator'@'175.20.5.104' (using password: YES)","Details":null};
ноя 07 17:03:01 workmail-02 deployer[2089060]: err discovery cluster: role: bibliodb, status:500, response: {"Code":"ERROR","Message":"Error 1045: Access denied for user 'orchesrator'@'175.20.5.104' (using password: YES)","Details":null};
ноя 07 17:03:01 workmail-02 deployer[2089060]: err discovery cluster: role: swadb, status:500, response: {"Code":"ERROR","Message":"Error 1045: Access denied for user 'orchesrator'@'175.20.5.104' (using password: YES)","Details":null};
ноя 07 17:03:01 workmail-02 deployer[2089060]: err discovery cluster: role: bizdb, status:500, response: {"Code":"ERROR","Message":"Error 1045: Access denied for user 'orchesrator'@'175.20.5.104' (using password: YES)","Details":null};
ноя 07 17:03:01 workmail-02 deployer[2089060]: err discovery cluster: role: mirage, status:500, response: {"Code":"ERROR","Message":"Error 1045: Access denied for user 'orchesrator'@'175.20.5.104' (using password: YES)","Details":null};]
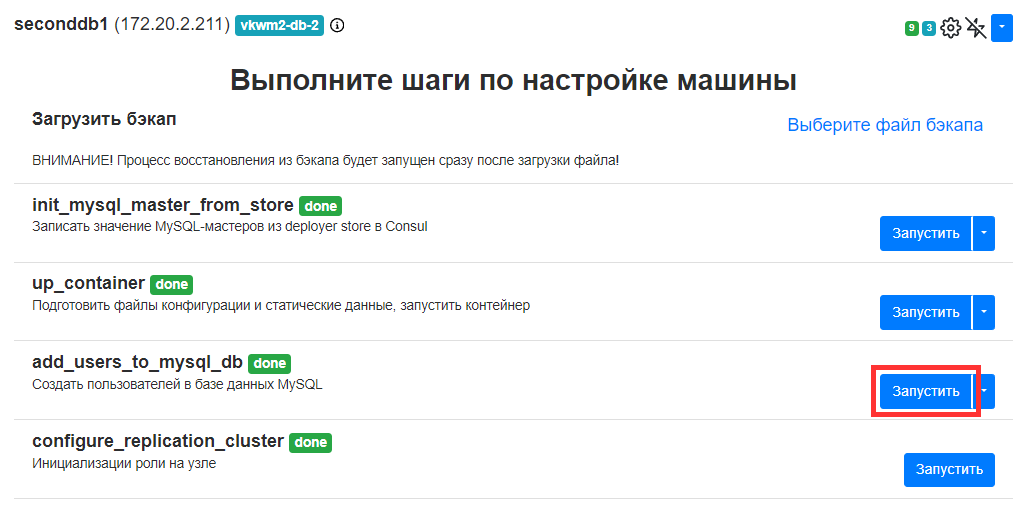
Решение
Нужно для каждой БД выполнить шаг add_users_to_mysql_db exec. Для примера логов выше, нужно выполнить этот шаг для следующих контейнеров: umi; seconddb; gravedb; rpopdb; fstatdb; bibliodb; swadb; bizdb; mirage.
Для каждого контейнера выполните следующие действия:
- Перейдите в веб-интерфейс установщика
http://server-ip-address:8888/. - Найдите контейнер в списке. Например, контейнер seconddb*.
- Нажмите на значок шестеренки.
-
Нажмите на кнопку Запустить напротив шага add_users_to_mysql_db exec.